地质第九章
第1节 碳储地质模型概述
第2节 碳储地质建模方法
第3节 碳储地质建模工作流程
一、概念
碳储地质模型是指反映碳圈闭的基本特征和空间分布规律的数据体。
目标:对碳储描述研究的最终成果的概括,它是对碳圈闭的形态、储层性质、规模大小及分布、流体性质及空间展布等的高度概括。是能够如实反映实际地质体特征的模型。
碳储地质模型的维数类型划分:
一维井模型:正确描述井孔柱状剖面碳储地质属性
二维层模型:正确描述剖面或平面井间二维碳储地质属性
三维整体模型:正确描述碳圈闭三维地质属性
二、建立井模型技术
目的:建立每口井各种开发地质属性的一维柱状剖面井筒一维剖面中最基本九项属性:
渗透层(储层)
含油层
孔隙度
有效层
含气层
渗透率
隔夹层
含水层
饱和度
比较成熟的现有技术
方法手段:以岩心及各种测试资料为基础,以测井为主要手段;
关键:建立把各种储层测井信息转换成开发地质属性的定性、定量模型。以实际静、动态资料对其进行标定。
二、建立井模型技术
现阶段存在的主要技术难点
渗透率还无法直接由测井方法求得(核磁共振测井有望)。现有测井解释方法都是间接求得的,误差30%;
当前建模中通常实用的方法是:用岩心数据建立的孔隙度~渗透率关系反求,最简单的办法是求孔隙度与渗透率的非线性关系,这样仍然有一定的误差。
三、建立层模型技术
目的:
建立储集体格架:把每口井中的每个地质单元通过井间等时对比联接起来——把多个一维柱状剖面构筑成二维地质体,建成储集体的空间格架。
关键点:
正确地进行小单元的等时对比,即要实现单个砂层的正确对比。可对比单元愈小,建立的储集体格架愈细。对于陆相沉积难度更大。
现有成熟和流行技术:
“旋回对比、分级控制”;
河流砂体小层对比,应用“等高程”,“切片”等方法;
地震横向追踪技术;
高分辨率层序地层学。
三、建立层模型技术
现有成熟和流行技术:
“旋回对比、分级控制”:
对于湖相沉积是相当有效的;
对于冲积相沉积、划分和对比砂组一般是有效的;连续沉积井段过长时难于控制。
河流砂体小层对比,应用“等高程”,“切片”等方法:现已比较广泛应用,但仍为有待深化的技术;
地震横向追踪技术:有待提高分辨率;
高分辨率层序地层学:露头—岩心—测井—地震综合,力争把准层序缩小到“十米级”。
三、 建立层模型技术
正在攻关的方向及内容:
冲积相 (重点是河流砂体)的层序(旋回) 识别标志:古土壤、遗迹化石,现发展遗迹相、古地磁学。前两者成功的报导较多,将同样遇到向井下转移的问题。
地震、测井结合高分辨率层序地层学:测井约束下的地震反演;
沉积学:在野外露头精细解剖各类沉积体的建筑结构要素,识别界面特征;
计算机自动对比:有模拟手工对比,有地质统计对比(见一些报导)。
四、三维碳储地质模型
目的:定量地给出储集体内空间各点的各种储层属性参数。
三维地质建模,就是运用计算机技术,在三维环境下,将空间信息管理、地质解译、空间分析和预测、地学统计、实体内容分析以及图形可视化等工具结合起来,用于地质研究一门新的技术。
第1节 碳储地质模型概述
四、三维碳储地质模型
三维地质模型的优越性:
$\textcircled{1}$ 逼真的三维动态显示效果,使不熟悉地质结构和构造复杂性的人对地质空间关系有一个十分直观的认识。
$\textcircled{2}$ 强大的可视化功能,可提高对难以想象的复杂地质条件的理解和判别,为勘察、井位论证等工作提供验证和解释。
$\textcircled{3}$ 强有力的数据统计和空间变化交互式分析工具,使地质分析功能加强,灵活性提高。
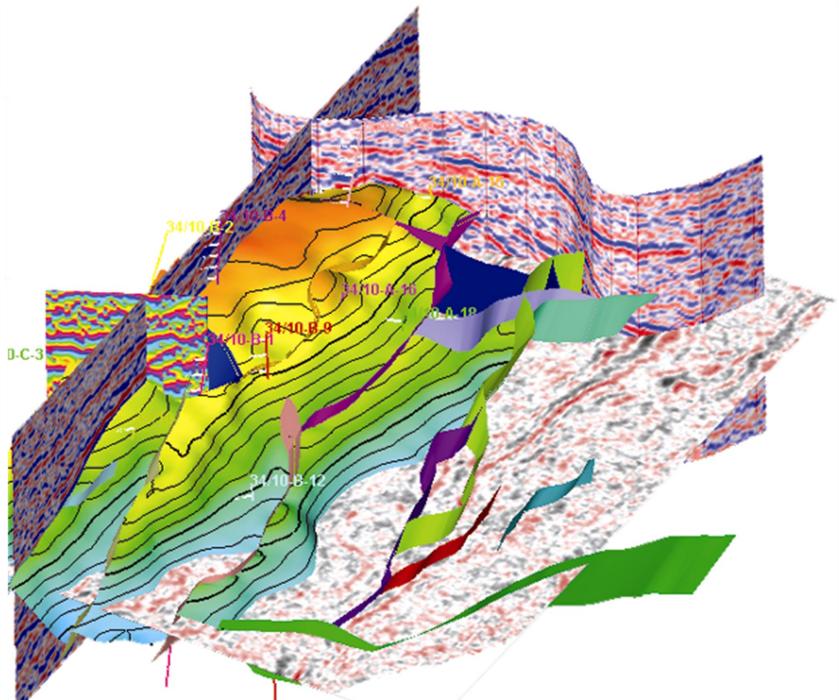
四、三维碳储地质模型
关键点:
如何依据已有井点(控制点头,原始样本点)的参数值进行合理地内插、外推井间未钻井区(预测点)的同一参数值。
内插、外推值误差愈小,地质模型精度就愈高。
影响精度的因素:
精、细度相互制约,单元愈细,提高精度愈难;
属性本身的非均质程度,非均质性愈强,提高精度愈难;精度与对其地质规律的认识程度成正比(原型模型、地质知识库)。
两类建模方法
确定性建模技术
确定性建模是对井间未知区给出确定性的预测结果,即试图从具有确定性资料的控制点出发,推测出点间(如井间)确定的、唯一的储层参数。
例如:1.传统的地质插值方法;2.地震反演技术;3.地质统计学克里金估值方法
随机建摸技术
用一组已知信息,依据一定的地质统计特征,用某一随机算法,模拟出一组等概率的实现。
确定性建模无论软件运行多少次,其结果是不变的。
随机模拟则产生许多可选的模型,各种模型之间的差别正是
空间不确定性的反映。
确定性建模方法
1.传统的地质插值方法:
人们曾尝试的各种插值算法对未知区域、特别是井间地区进行估计。
如简单线性内插法、三角网格法、曲面样条法、按距离加权平均法、距离反比权衡,趋势面作图法等。
这些算法所产生的结果均是确定性的。这些传统的插值算法,仅考虑到观测点与待估点之间的距离,而没有考虑到空间位置之间的相互关联,既地质规律所造成的储层参数在空间上的相关性,应用效果虽然不尽人意,但开创了用数学方法解决地质问题的先河。
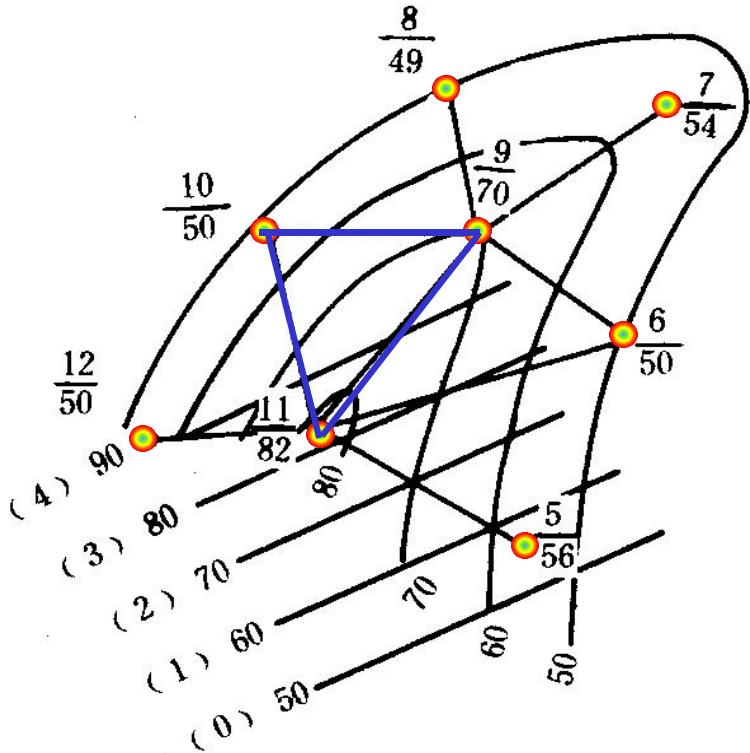
井号 标准层顶面海拔(m)
50构造等高线
确定性建模方法
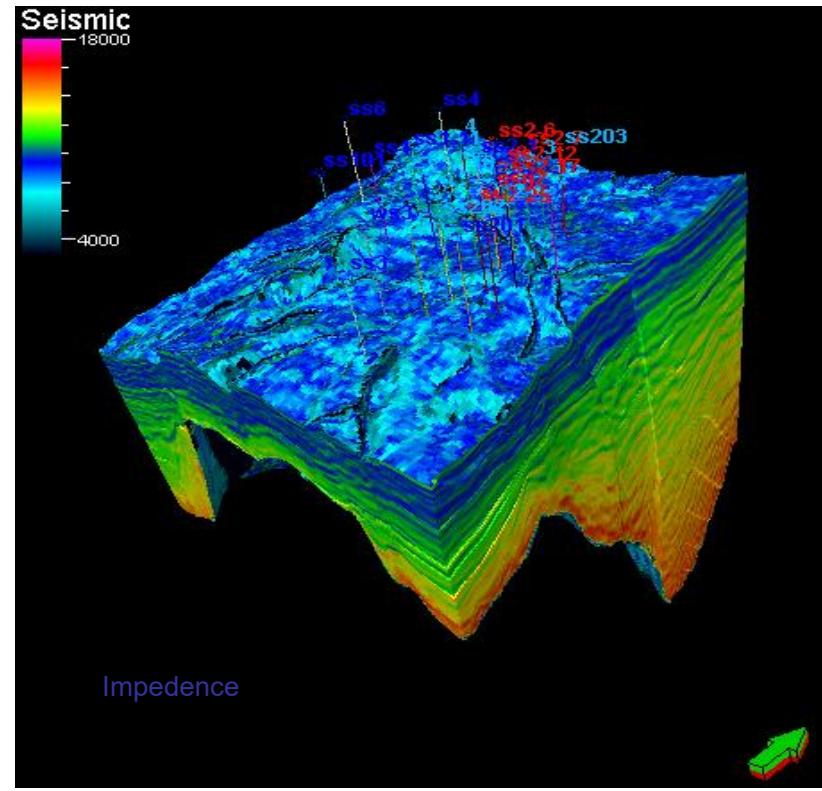
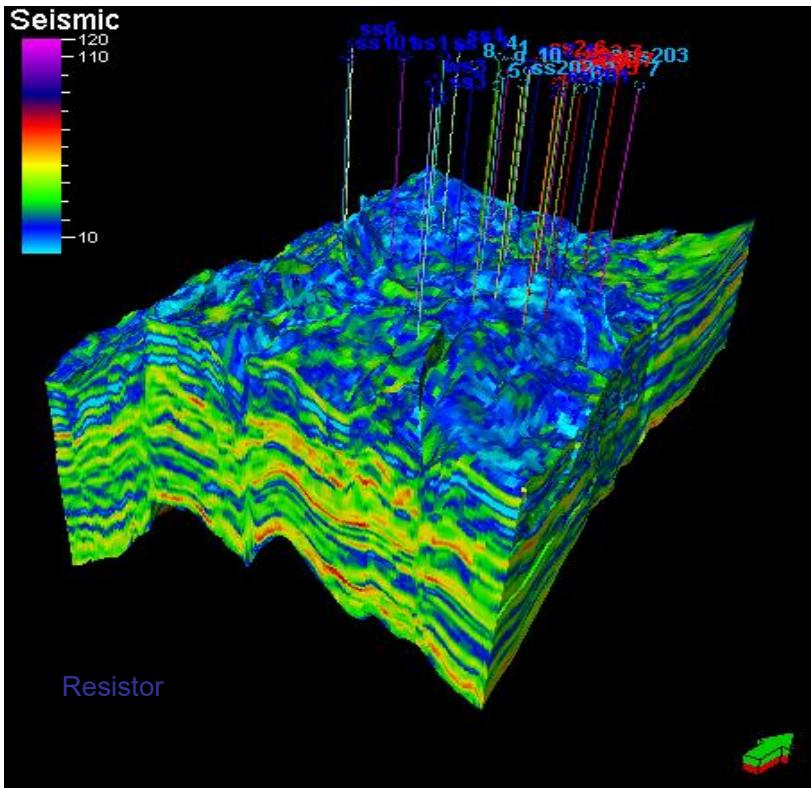
2.地震反演技术
地震反演技术主要应用地震资料,利用地震属性参数,如层速度、波阻抗、振幅等与储层岩性和孔隙度的相关性进行横向储层预测,继而研究储层的几何形态、岩性及储层参数的分布,建立储层岩性和物性的三维分布模型。
一般是针对盆地内某区块或有利储集相带的一套碳储层系进行研究。研究厚度相对较大,一般在十几米~几十米范围内,在地震剖面上主要表现为一个反射同相轴或几个同相轴组成的反射波组。
目前遇到的关键问题是分辩率还满足不了碳储地质研究单砂体的要求。但对其前景大家都寄以很大的厚望。
1 确定性建模方法
2.地震反演技术
分辨率问题
三维地震资料具有覆盖面广、横向采集密度大的优点,其主要问题是垂向分辨率低(为主波长的1/4,一般为20米左右),比测井资料的分辨率(一般0.5m左右)低得多。对于我国普遍存在的陆相储层(以“米级”规模薄层间互的砂泥岩)来说,常规的三维地震很难分辨至单砂体规模,而仅为亚段或段规模,而且预测的储层参数(如孔隙度、流体饱和度)的精度较低,往往为大层段的平均值。因此,在应用三维地震资料(结合井资料和VSP资料)进行储层建模时,所建模型的垂向网格较粗(一般20米左右,通过地震反演技术使垂向分辨率提高 至4—8米 )。这类模型可满足CCUS评价的要求。
但是,这一较低垂向分辨率的储层模型乃至地震属性(振幅、速度或波阻抗)本身,可作为高分辨率储层建模的宏观控制(或趋势),以便综合应用井资料和地震资料建立垂向网格较细的储层模型,这比单纯应用井资料建立的储层模型精度更高。
1 确定性建模方法
3.地质统计学克里金估值法
80年代,地质统计学方法受到人们的普遍重视。在算法上步入克里金插值阶段。克里金插值是一种局部估计的方法,它提供了区域化变量在一个局部区域平均值的最佳估计,即最优(估计方差最小)、无偏(估计误差的数学期望为0)的估计。克里金估计根据实测数据,应用变差函数(或协方差函数)所提供的空间结构信息,通过求解克里金方程组计算局部估计值。该方法充分考虑了空间数据的结构性和随机性,从而使克里金方法优于其他一些传统的统计方法。
克里金插值方法考虑了储层内部属性参数平面及垂向上的各向异性,在三维网格化过程中,依据储层的成因特点,在各方向上采用不同的变程做为约束条件,即插值搜索范围为一个三种轴向半径不同的椭球体,其长轴方向代表储层参数发育的优势方向,因此,算法上较距离反比加权等更加科学。
1 确定性建模方法
3.地质统计学克里金估值法
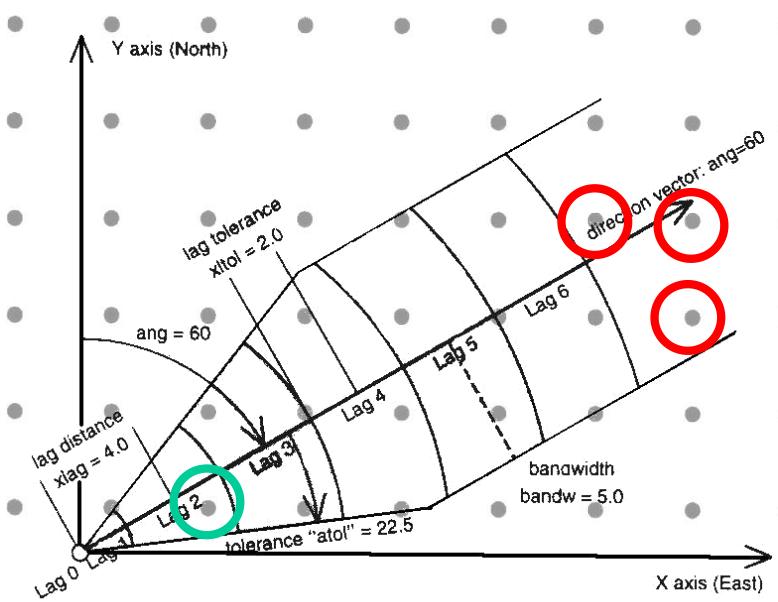
变差函数分析
储层参数空间结构分析就是对储层参数进行一系列统计分析,研究储层的空间结构及各储层参数的空间分布的连续性和各向异性。
目前,研究数据变量空间连续性或各向异性的方法和手段有多种,如协方差函数、相关函数等,但是这些方法只能概括地质体某一特征的整体概况而无法反映其局部变化特征,地质统计学中引入变差函数。
确定性建模方法
3.地质统计学克里金估值法
$\textcircled{1}$ 变差函数分析
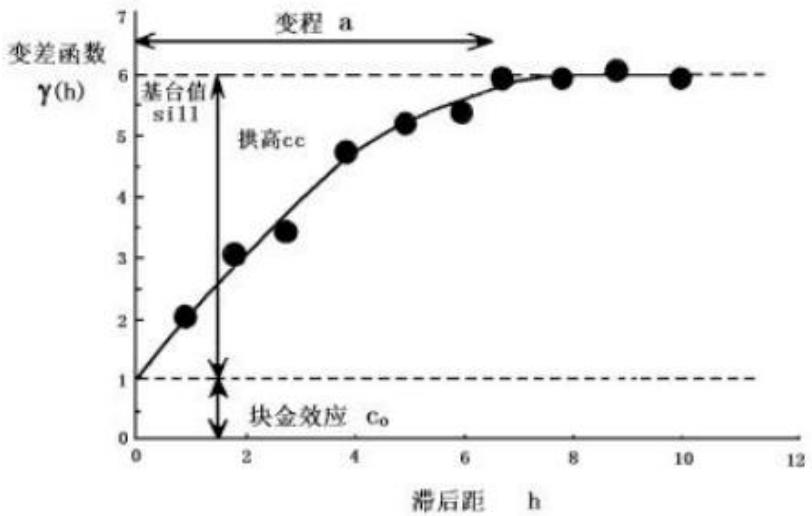
变差函数:假设空间点只沿某一方向上变化,那么我们把区域化变量在两点处的值之差的方差之半定义为在该特定方向上的变差函数,它表示区域化变量的两值Z(x)、Z(x+h)的变异程度。记为:
在实际工作中,实验变差函数通常用计算算术平均值的方法来获得,即:
变异函数模型的拟合
对实验变异函数做最优拟合,从而确定变异函数的块金常数Co、变程a和基台值C(0)。选择并建立合适的变异函数模型是地质统计学的基础。
常用的变异函数模型有四种:
c0 3(1)球状模型: c0
0 h =0(2)指数模型:h 0
(3)高斯模型: c
(4)幂模型:
第2节 碳储地质建模方法
$\textcircled{1}$ 变程:
变程是指区域化变量在空间上具有相关性的范围。在变程范围之内,数据具有相关性;而在变程之外,数据之间互不相关,即在变程以外的观测值不对估计结果产生影响。具体来说,假如某种属性在空间上是各向同性的,也就是说,在各个方向上的变化一致,那么,以某一观测,点为球心,以变程为半径画一个球体,该观测点和球体内的所有其他数据相关;反之,超出这个范围的数据与这点无关。因此,变程的大小反映了变量空间相关性的大小,变程相对较大意味着该方向的观测数据在较大范围内相关;反之,则相关性较小。
$\textcircled{2}$ 块金值
变差函数如果在原点间断,这在地质统计学中被称为“块金效应”,表现为在很短的距离内有较大的空间变异性。它可以由测量误差引起,也可以来自矿化现象的微观变异性。在取得有效数据的尺度上,这种微观变异性是不可得到的。在数学上,块金值相当于变量纯随机性的部分。如果无论h多么小,两个随机变量都不相关,这种情况称为纯块金效应。
$\textcircled{3}$ 基台值
基台值为变量在空间上总变异性的大小,即为变差函数在h大于变程的值,为块金值和拱高之和。所谓拱高,为在取得有效数据的尺度上,可观测得到的变异性幅度大小。当块金值等于0时,基台值即为拱高。
克里金插值方法
1.基本原理
下面以普通克里金为例说明克里金的估值方法。
设x1,…, 为区域上的一系列观测点, ,…, 为相应的观测值。区域化变量Z(x)在 处的随机变量 可采用一个线性组合来估计:
式中? −权系数。
从式(3-39)可知,求取 的关键是利用统计模型确定? 的值。根据无偏性和估计方差最小的标准选取? :
从这两个关系式可推导出求取? 的克里金方程组。
首先,从二阶平稳假设出发,可知E[Z(x)]为常数(在搜寻邻域内),表达式为
可得关系式:
为了使估计方差达到最小,可利用拉格朗日乘子法,式(3-27)对各个? 的偏导数等于0:
$$ \frac {\partial}{\partial \lambda_ {j}} \left[ E \left[ Z ^ {*} \left(x _ {0}\right) - Z \left(x _ {0}\right) \right] ^ {2} - 2 \mu \sum_ {i = 1} ^ {n} \lambda_ {j} \right] = 0 j = 1, \dots , n \tag {3-44} $$
式中?-拉格朗日常数。
进一步推导可得到 阶线性方程组,即克里金方程组:
式中 点与j点之间的距离;
-空间i点与j点间的协方差;
-空间待估点与j点间的协方差。
当随机函数不满足二阶平稳,而满足内蕴假设时,可用变差函数 来表示克里金方程组:
通过求解上述方程组,可得到一系列 ,据此可求解估计点的克里金估计值。最小的估计方差,即克里金方差可用以下公式求解:
或用变差函数表示:
克里金估值的基本步骤
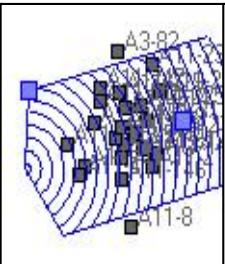
1)数据准备
针对研究区,准备已有的观测数据。如图3-24所示。在平面上S1、S2、S3和S4处取了四个样品,其孔隙度分别为Φ1=21%、Φ2=17%、Φ3=16%、 ,要求估算S0点处的孔隙度 。其他参数值为:块金值 ,变程 ,拱高c=15。
(1)球状模型:
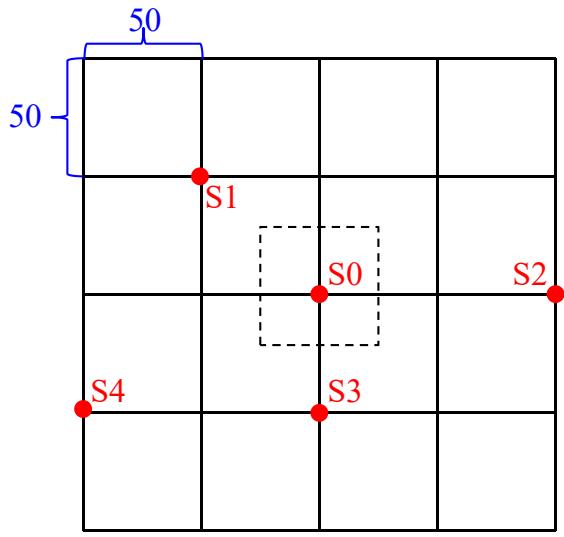
取样点平面位置图
2)结构分析
根据上述数据,参考原型模型,确定储层的变差函数。研究表明,研究区Z(x)为二阶平稳,平面上的二维变差函数为一个各向同性的球状模型。
变差函数为
3)求解权系数
通过克里金方程组,求取权系数。
普通克里金方程组(3-46)可变换为矩阵形式:[K][?]=[M],则:
在上述矩阵中,[?]为权系数矩阵;[K]为观测点之间的协方差矩阵; 是指S1号点与S2号点之间的协方差值,其他同理;[M]为待估点与取样点之间的协方差矩阵; 表示指待估点与1号点之间的协方差值,其他同理。
上述矩阵求解可分为以下三个环节。
(1)求解矩阵中的协方差值。
协方差矩阵中的协方差为未知数。在解矩阵求权系数?前,需要先求协方差。
协方差的求取可根据两个公式,即变差函数表达式(3-49)和变差函数与协方差函数的关系式 ,可得
将计算的协方差代入式(3-34)得到如下矩阵:
$$ \begin{array}{c c c c c c} 1 8 & 0. 9 2 & 3. 7 3 & 3. 7 3 & 1 & 7. 3 8 \\ 0. 9 2 & 1 8 & 3. 7 3 & 0 & 1 & 4. 6 9 \\ [ 3. 7 3 & 3. 7 3 & 1 8 & 4. 6 9 & 1 ] ^ {- 1} [ 9. 4 9 ] = [ \lambda_ {3} ] \\ 3. 7 3 & 0 & 4. 6 9 & 1 8 & 1 & 3. 7 3 \\ 1 & 1 & 1 & 1 & 0 & 1 \\ & & & & & - \mu \end{array} $$
(2)解矩阵,求权系数。
解上述矩阵,便可求得四个取样点对待估点S0估值的贡献(双系数)。通过计算,四个权系数分别是:
(3)加权求和,计算估值。
根据四个点的观测值及计算的权系数,进行加权求和,即可计算S0点的估值。
二、随机建模方法
虽然地下储层本身是确定的,但人们去认识它时就可能出现随机性。这由于:
资料信息不足;
资料信息本身有不确定性;
一些储层属性的地质规律有一定的随机性。
随机建模方法:用一组已知信息,依据一定的地质统计特征,用某一随机算法,模拟出一组等概率的实现。
关键点:
一)丰富的地质知识库及其表征的碳储层统计结构特征,
(二) 能够表征统计结构特征的随机算法。
二、随机建模方法
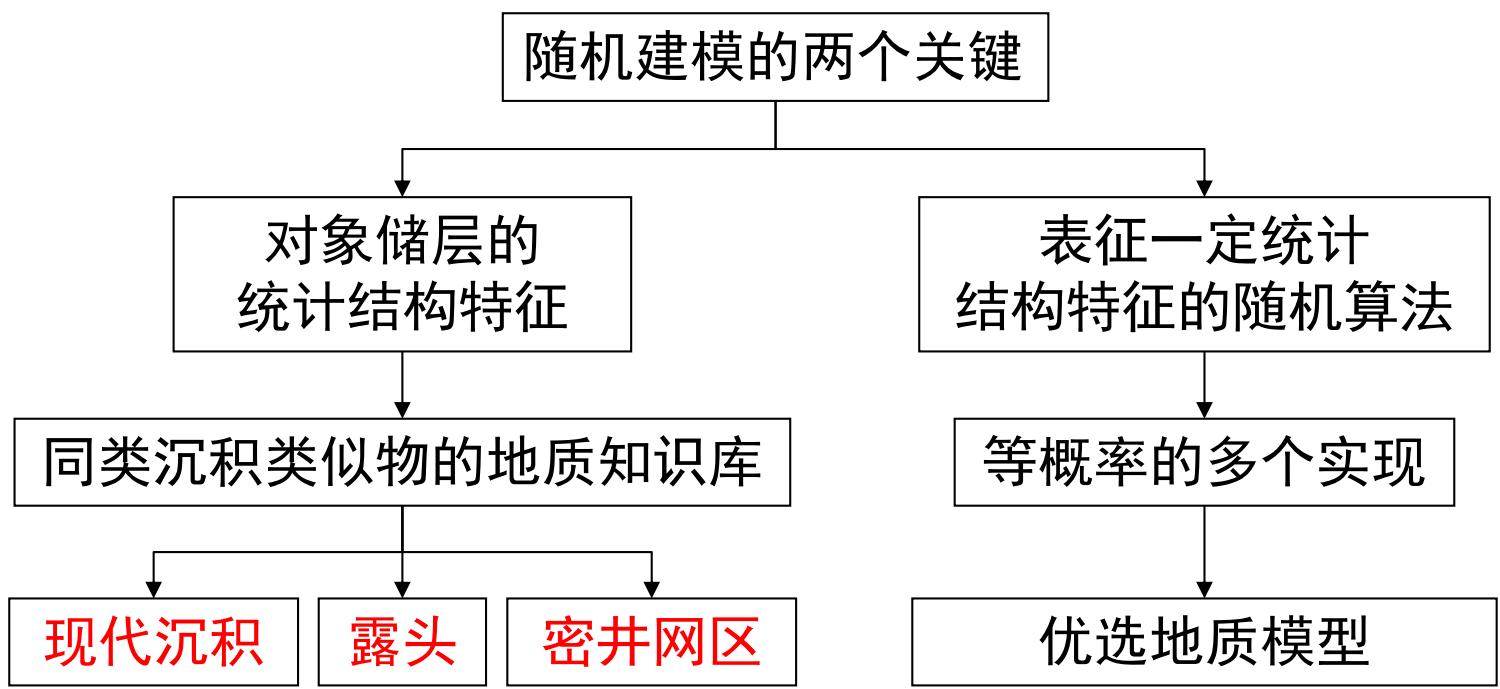
随机建模方法目前正在发展、探索的技术和问题
各类沉积储层的原型模型,丰富地质知识库;
各种算法对各类储层的适应性;
发展新的算法;
如何应用综合地震、地质、测井资料。
二、随机建模方法
(一)地质知识库及其统计结构特征
储层地质知识库是指在露头、现代沉积和密井网开发区内,对各类参数进行统计分析的基础上建立的能够定量表征储层特征参数统计分布规律的地质知识,它们是储层随机建模的控制条件。
岩性(相)及序列
空间组合关系
几何形态
n 规模
岩相(沉积相)平面拼合关系
n 物性参数分布(分布概率、平均值、中值、标准偏差、最大值、最小值、变异系数及各参数间的相关系数等)
电性响应特征
二、随机建模方法
(一)地质知识库及其统计结构特征
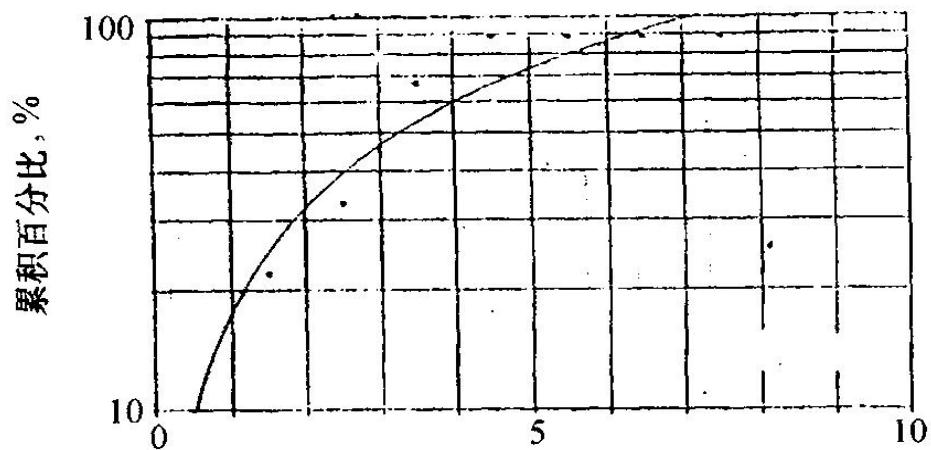
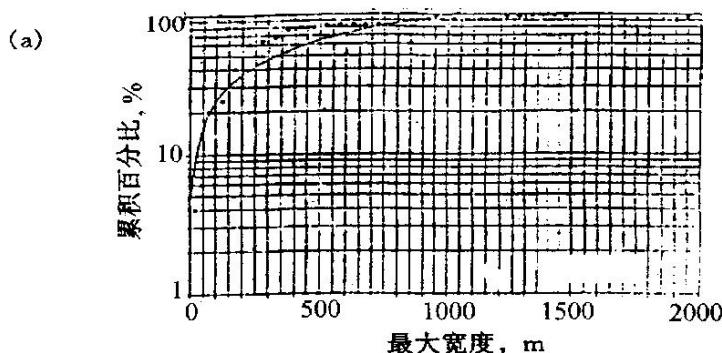
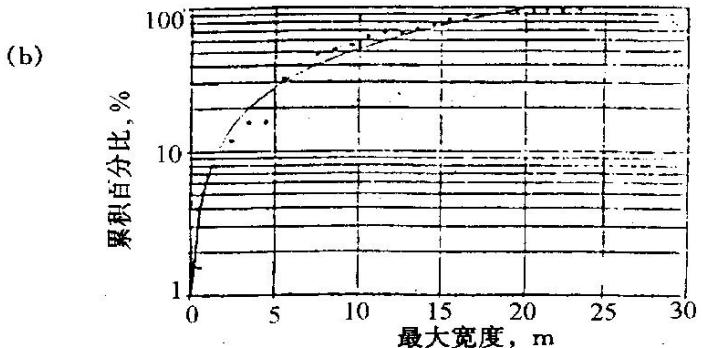
最大最度,km
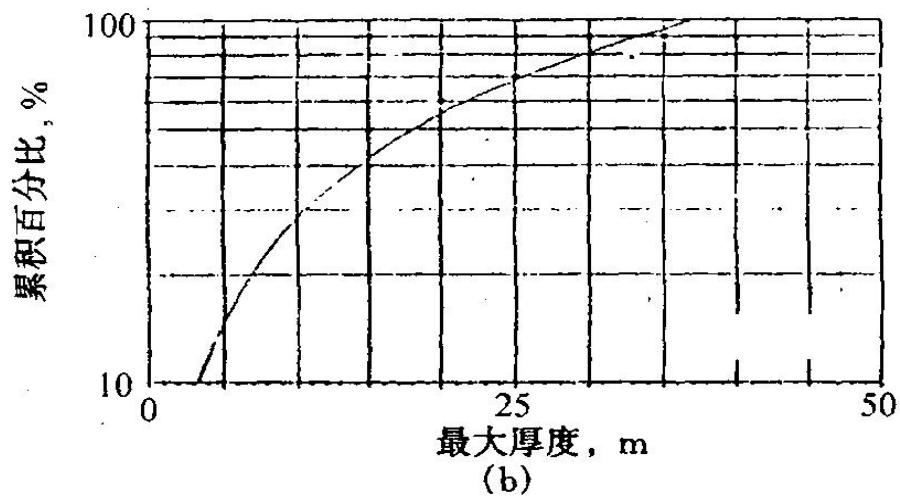
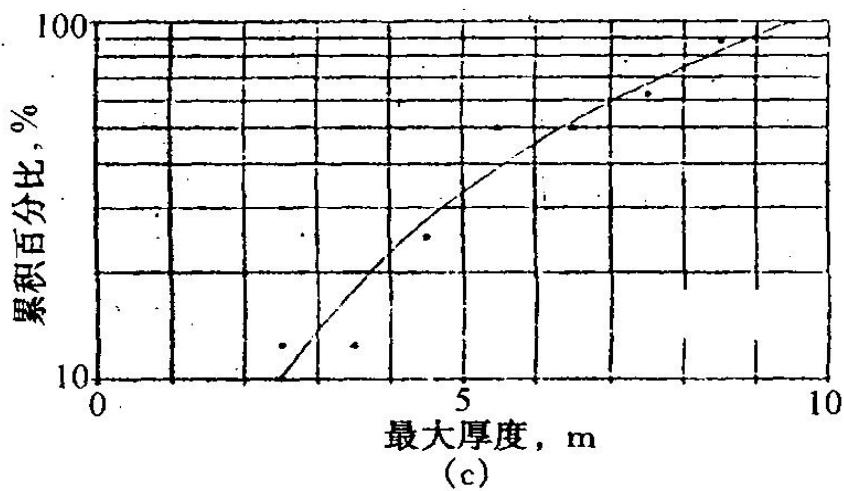
分支河口坝砂体的极限图(Lowry等,1989)
(a)宽度;(b)厚度;(c)长度
二、随机建模方法
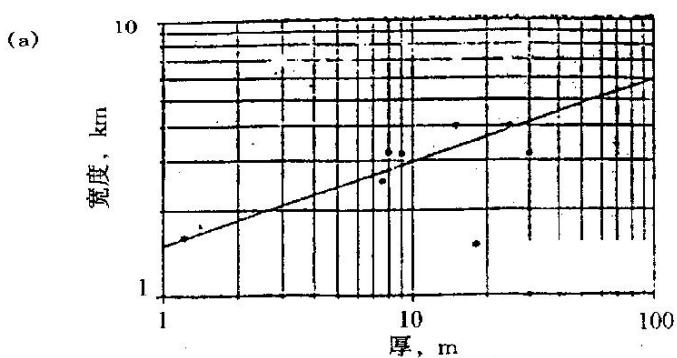
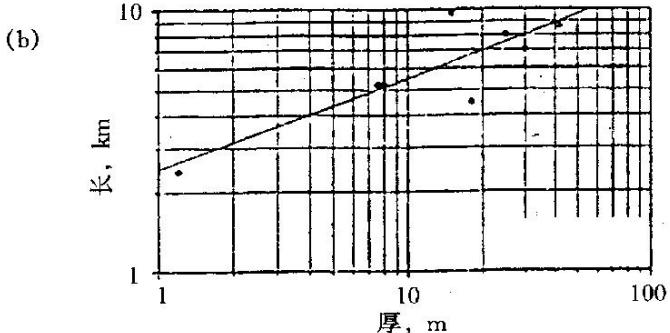
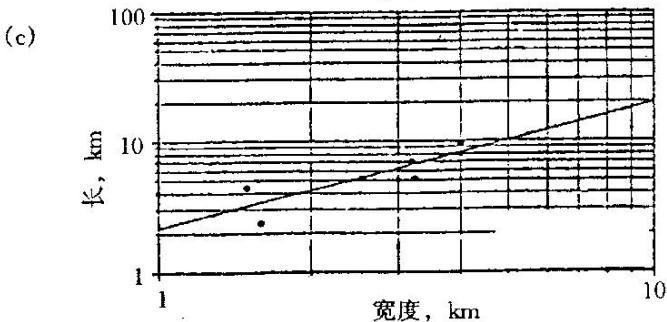
分支河口坝砂岩的宽度、厚度和长度之间的关系(Lowry等,1989)
(a)厚度对宽度;(b)厚度对长度;(c)宽度对长度
(一)地质知识库及其统计结构特征
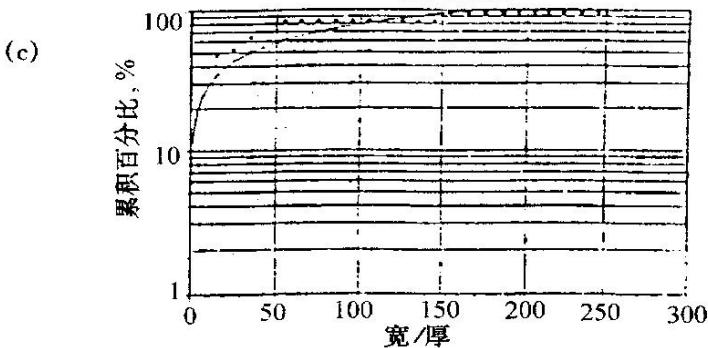
分支河道砂体的极限图
(Lowry等,1989)
第2节 碳储地质建模方法
二、随机建模方法
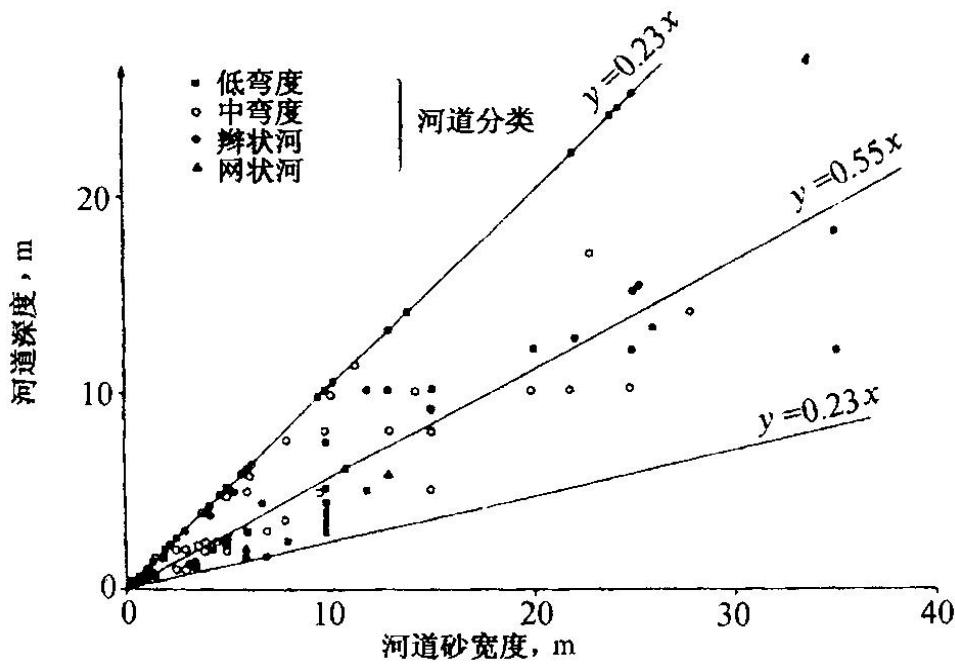
Fielding和Crane (1987)的相关图
(一)地质知识库及其统计结构特征
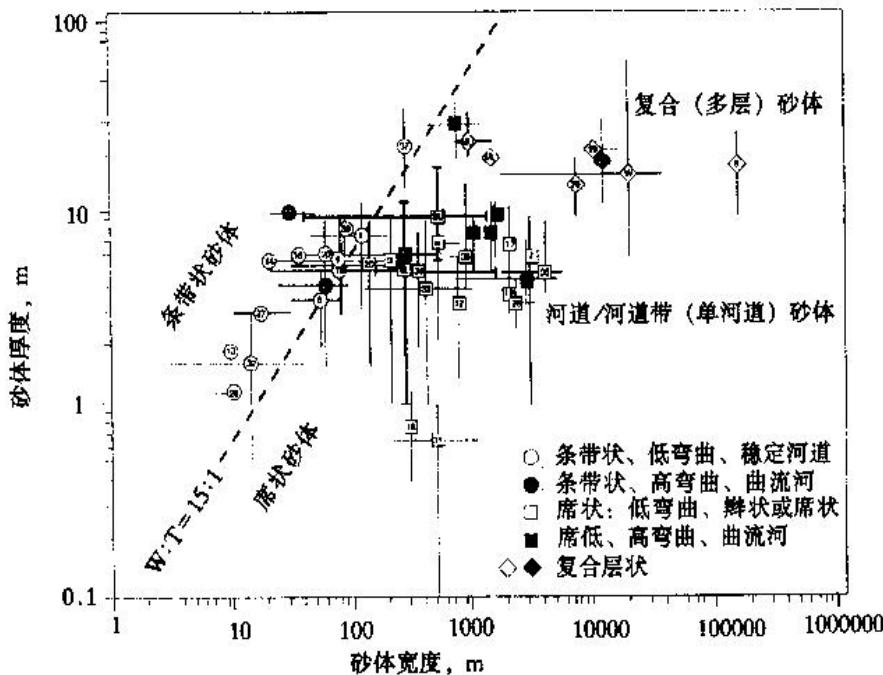
砂体厚度与宽度的关系(据Cowan,1991修改)数据点为平均值,十字代表了变化范围
第2节 碳储地质建模方法
二、随机建模方法
(一)地质知识库及其统计结构特征
组成 Kayenta组结构的主要岩相组合
主要岩相类型渗透率数据统计
二、随机建模方法
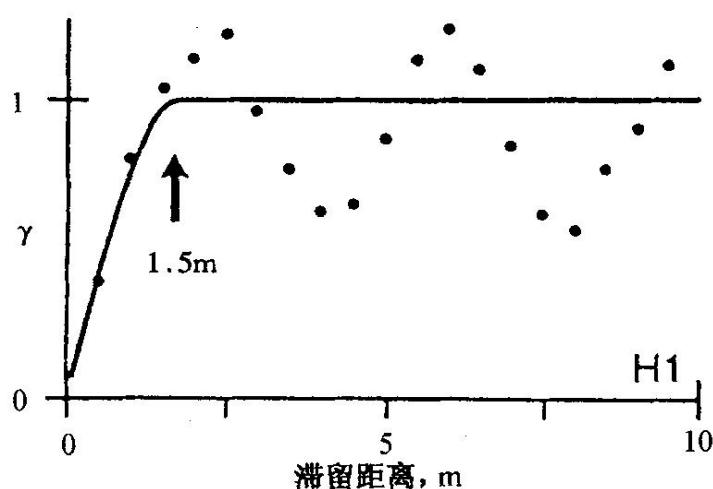
(一)地质知识库及其统计结构特征
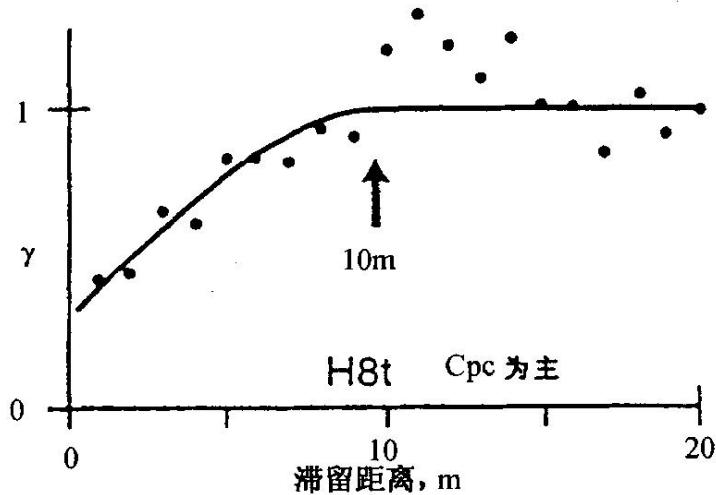
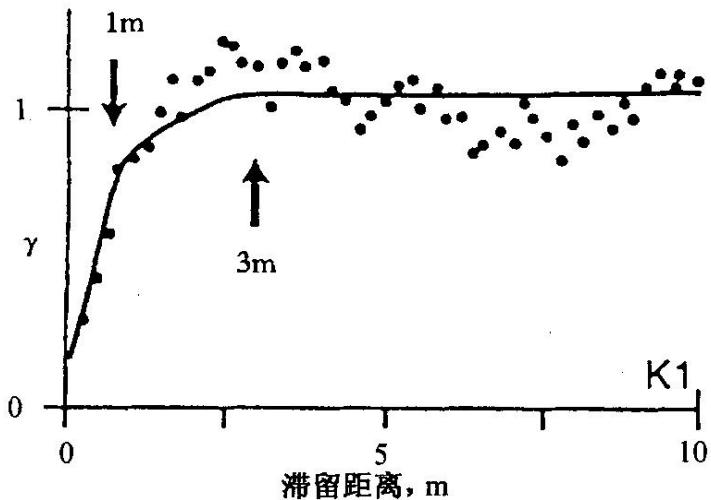
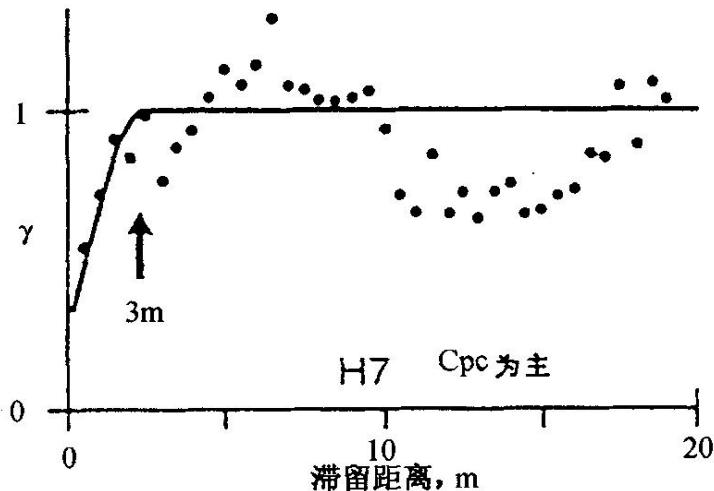
图4-20露头处收集的渗透率数据空间分布半变量图
观察的相关结构的范围用箭头表示,(a)和(b)为纵截面;(c)和(d)为水平截面
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
随机建模方法分类
从模拟单元的角度来分,随机模拟可以分为:基于目标和基于象元
基于目标随机模型其基本模拟单元为目标物体(即是离散性质的地质特征,如沉积相、流动单元等),主要方法为标点过程。
基于象元的随机模型以象元(相当于储层网格化后的单个网格)为基本模拟单元,既可用于连续性储层参数的模拟,也可用于离散地质体的模拟。
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
从随机模拟方法可以分为二大类:离散型、连续型
从而建立的模型称为离散模型、连续性模型
离散模型主要描述一个离散性质的地质特征,如沉积相分布、砂体位置和大小、泥质隔夹层的分布和大小,裂缝和断层的分布、大小、方位等。
连续性模型主要描述连续变化的地质参数的空间分布,如孔隙度、渗透率、流体饱和度等岩石物理参数的空间分布。
在实际碳圈闭中,离散性质和连续性质是共存的。将上述两类模型结合在一起,则构成混合模型,亦称为二步模型,即第一步建立离散模型,描述储层大范围的非均质特征(储层结构)特征,第二步是在离散模型的基础上建立表征岩石参数空间变化和分布的模型,由此便获得了混合模型。
二、随机建模方法
(二)能够表征统计结构特征的随机算法
常见随机模拟方法分类
离散方法:以对象为基础的模拟方法;连续型方法:以象元为基础的模拟方法
条件模拟:忠实于采样点资料的方法;非条件模拟:已知采样点资料也可以修
改的方法
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
(3)随机模拟方法分类
①离散模型
离散模型是为了描述具有不连续性质的地质特征而开发的,如河流相地层中砂体的位置和几何分布,砂岩中页岩夹层的分布和规模,裂缝和断层的分布、方向和长度,以及岩相模拟等。
• 在以上各种情况下,空间中的一个点属于有限分类数中的一个,而且仅有一个,随机模型控制着在每一点该分类的数值如何交互影响。例如,该模型可以控制一个砂体可以怎样侵入到另一个砂体中;裂缝是否横切,怎样横切,不同的岩相怎样相互牵制和排斥等等。
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
(3)随机模拟方法分类
离散模型
基于目标体的模拟
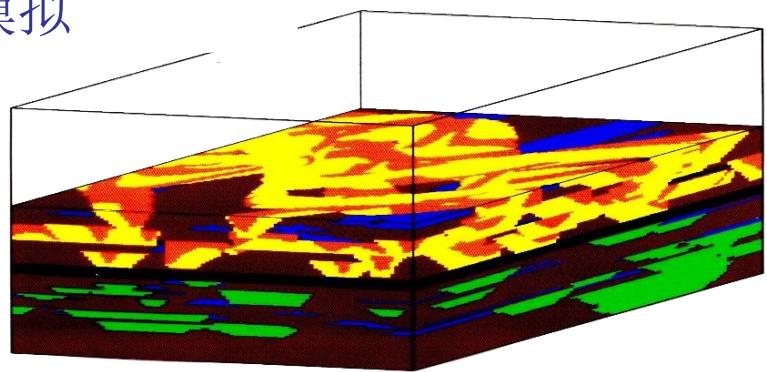
地质几何体的三维模拟
模拟沉积历史
统计数据来自: 岩芯、测井、地震、和露头
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
(3)随机模拟方法分类
离散模型
基于目标体的模拟
离散模型用于描述离散性质的地质特征,如河流沉积环境的砂体(河道、决口)位置和大小,砂岩中悬浮的页岩的分布和大小,裂缝和断层的分布、方向和长度,相模拟等。
随机模拟可以控制一个砂体如何侵蚀另一个砂体,裂缝如何走向,不同相如何相对应等。不用实际流动模拟就可以计算出可注水砂的比例。在建模型时,地质思路是很关键的。
常见的离散型模型有:示性点过程、马尔科夫随机场、截断高斯、两点直方图。
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
示性点过程的储层建模方法最早有挪威学者提出,是一种基于目标的随机建模方法。该方法应用了随机几何学中点过程理论。
点过程提供各种模型来研究点的不规则空间分布。这些点在空间上的分布可以是完全独立的(如泊松点过程),也可以是相互关联的或排斥的(如吉布斯点过程)。示性点过程则是一种特殊的点过程。
一个点过程,对其上赋予一个特征值(或称为一个属性、或示性)时,就称为示性点过程。该方法在模拟地质体的空间分布是十分有用的,它的基本思路就是根据点过程理论先产生这些物体的中心点在空间上的分布,然后再将物体性质(如物体的几何形态、大小、方向等)标注于各点上,即通过随机模拟产生这些空间点的属性,并与已知的条件信息进行匹配
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
相和砂体分布定量模拟
离散模型用于描述离散性质的地质特征,如河流沉积环境的砂体(河道、决口)位置和大小,砂岩中悬浮的页岩的分布和大小,裂缝和断层的分布、方向和长度,相模拟等。
随机模拟可以控制一个砂体如何侵蚀另一个砂体,裂缝如何走向,不同相如何相对应等。不用实际流动模拟就可以计算出可注水砂的比例。在建模型时,地质思路是很关键的。
常见的离散型模型有:示性点过程、马尔科夫随机场、截断高斯、两点直方图。
二、随机建模方法
(二) 能够表征统计结构特征的随机算法岩相模拟
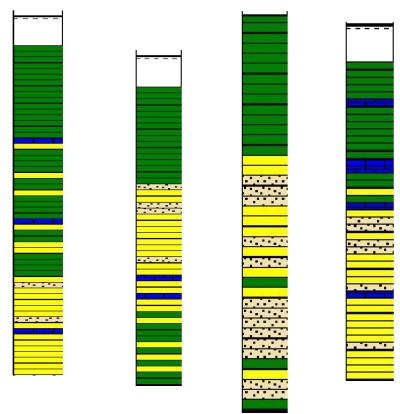
井的岩性资料
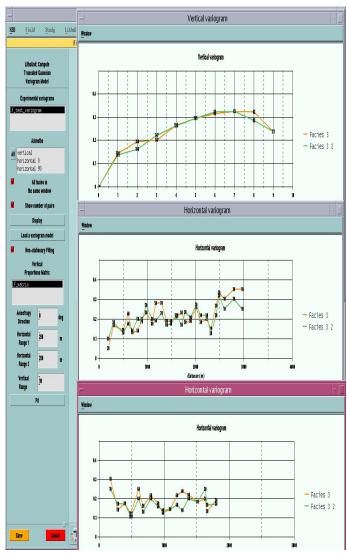
层的地震属性
垂直岩性比例
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
(3)随机模拟方法分类
②连续模型
对于每一变量,储层空间内的每一个点都有其不同的值。随机模型可以描述这些变量的中值情况,或可能的横向、纵向变化趋势;中值的可变性;与邻点之间的对比可靠程度。如果不仅是一个变量,则还可描述所研究的各变量之间的协变性。
除了中值的变化趋势,大多数连续模型假定储层中各参数具有某种程度的稳定性。即储层的统计特征在空间中并不改变。这一假设并不总是正确的。对所研究储层的地质认识和经验,对于建立连续模型也是十分重要的,但是这种方法似乎更为机械。
连续模型用来描述连续变化的地质现象,如岩石特征、地震速度和量纲参数(如储层顶面、OWC等)。
二、 随机建模方法
(二) 能够表征统计结构特征的随机算法
(3)随机模拟方法分类
$\textcircled{2}$ 连续模型
基于象素的模拟
岩性、孔隙度、渗透率的三维模拟
表征主要非均质性和统计特征
统计数据来自: 岩芯、测井、地震、和露头
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
(3)随机模拟方法分类
$\textcircled{2}$ 连续模型
连续型模型用于描述储层参数连续变化的特征,如孔隙度、渗透率和含水饱和度等。
模拟退火模拟法
顺序指标模拟法
分形随机函数法
马尔科夫随机域法
LU分解法
转带法
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
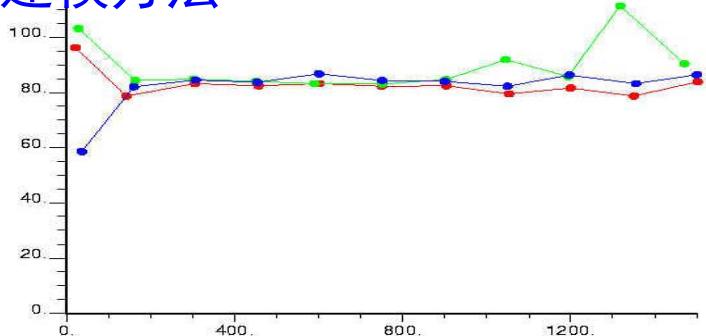
Distance
孔隙度三维变差函数图
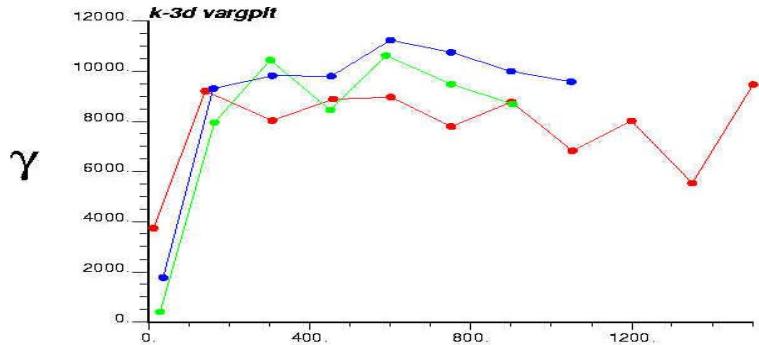
Distance
渗透率三维变差函数图
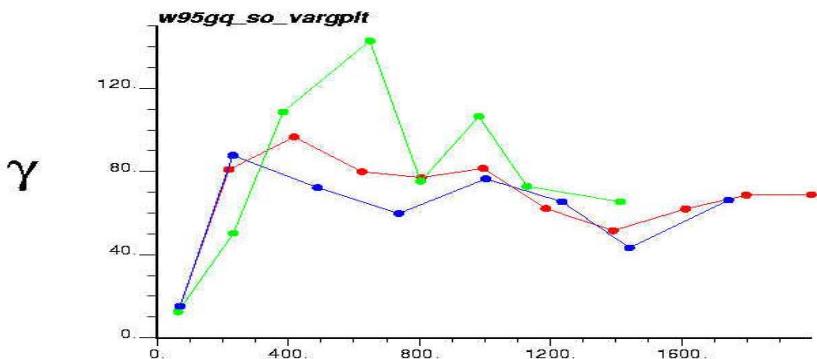
DISTANCE
含油饱和度三维变差函数
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
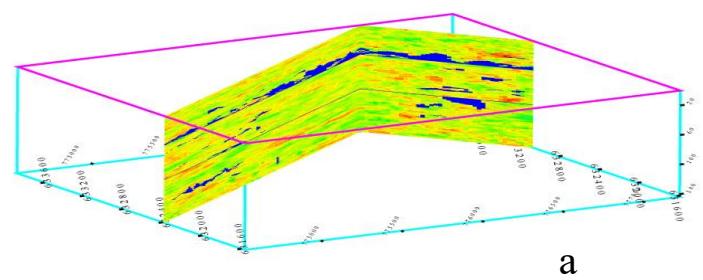
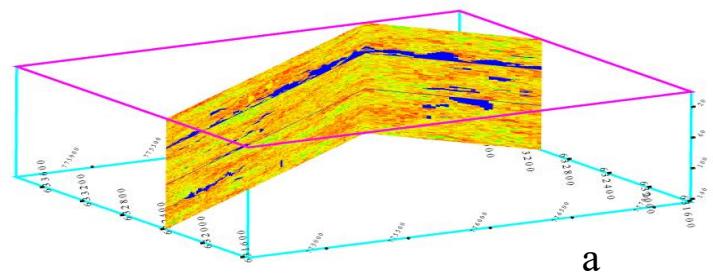
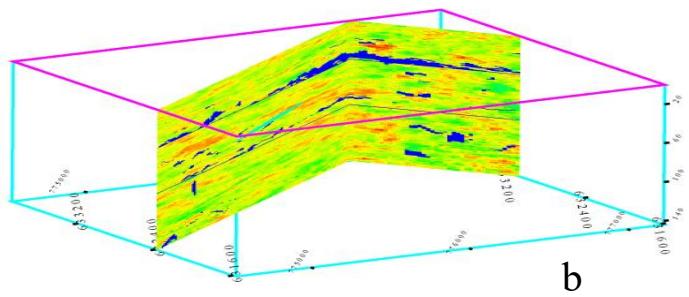
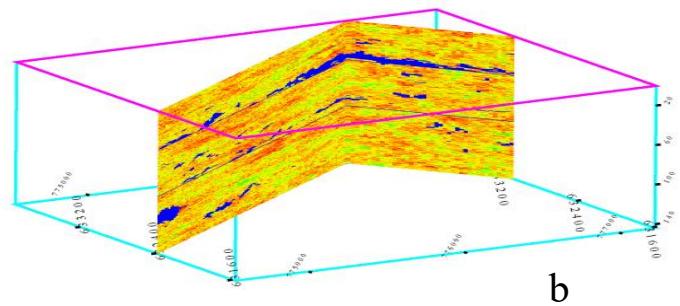
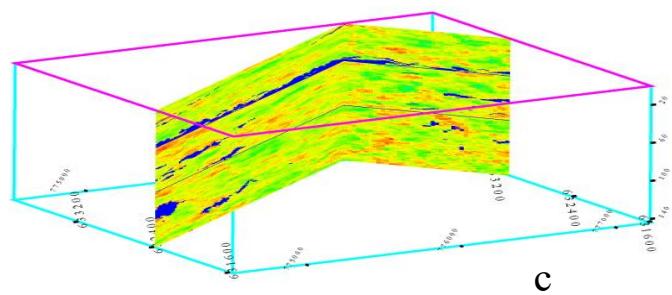
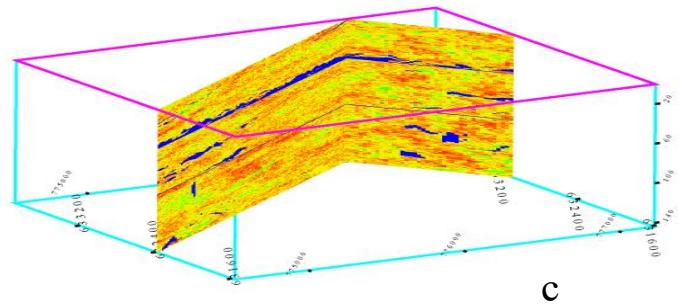
三维孔隙度建模的三个实现(XZ-YZ切片)
三维渗透率建模的三个实现(XZ-YZ切片)
二、随机建模方法
各 (二)能够表征统计结构特征的随机算法
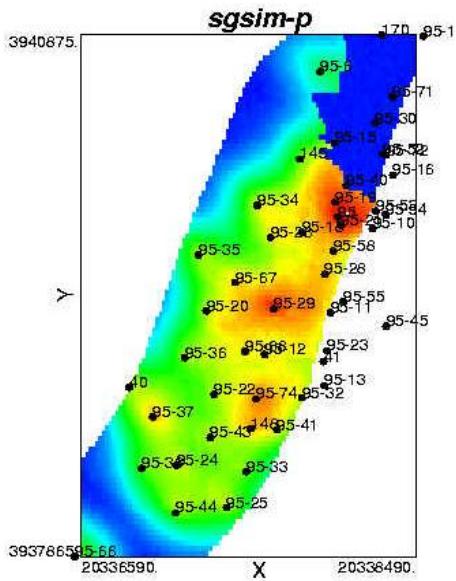
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
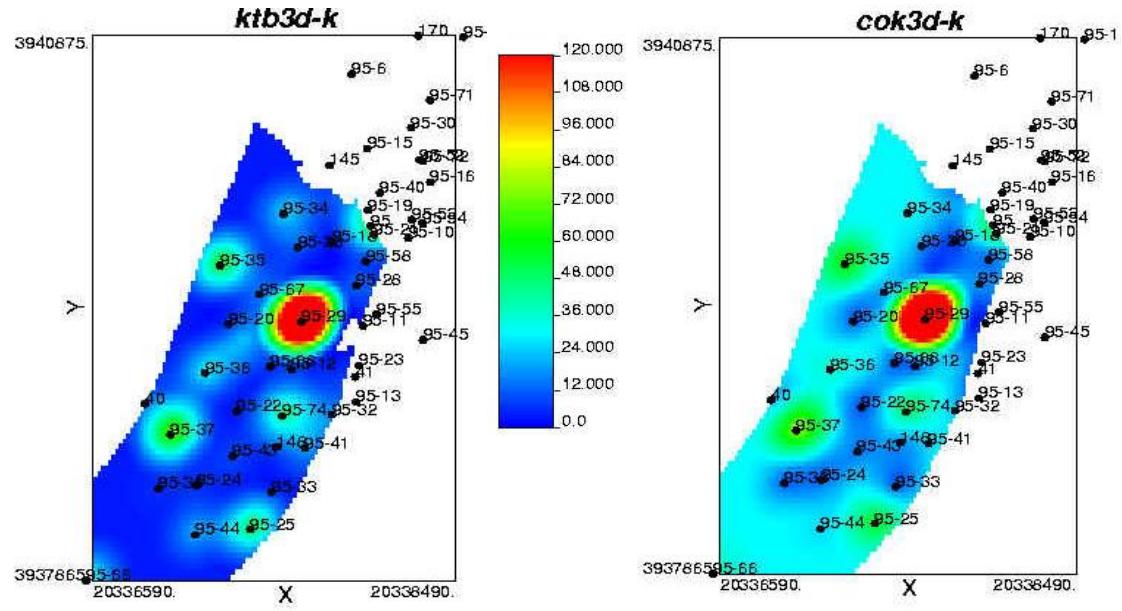
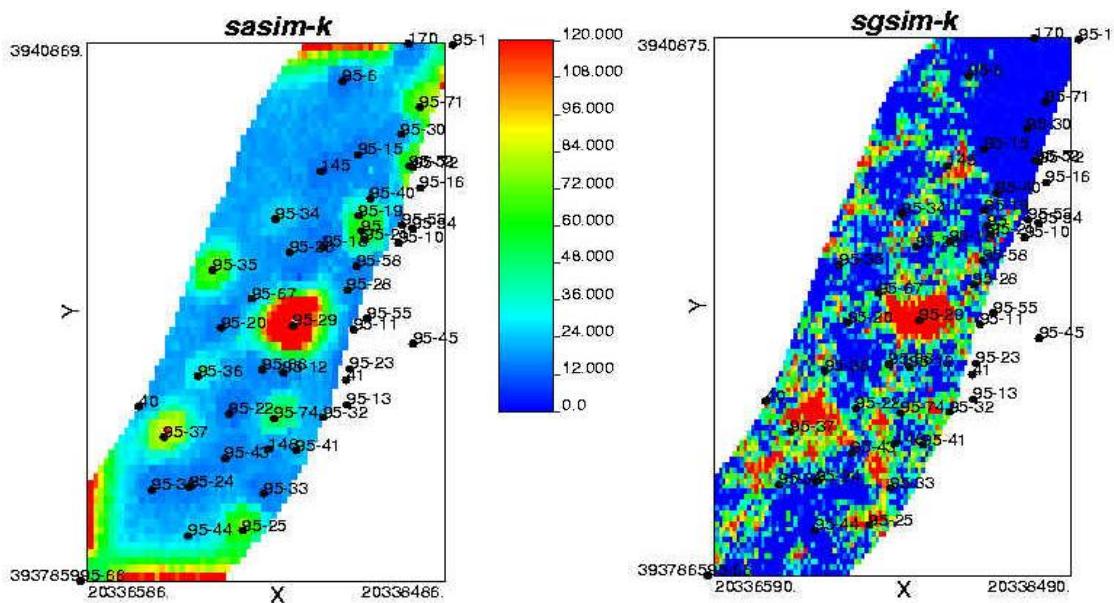
二、随机建模方法
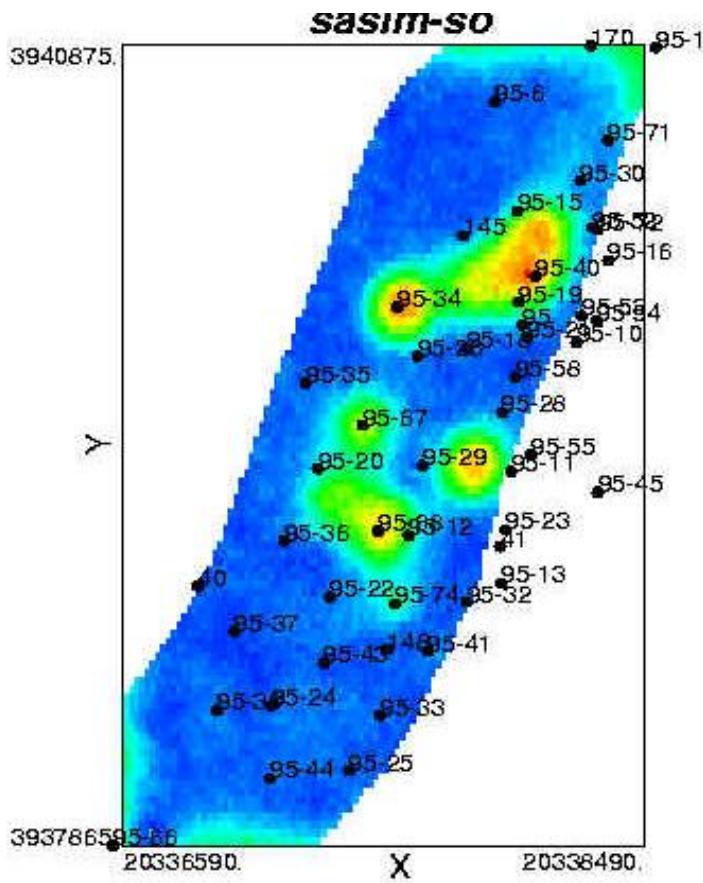
文95块55流动单元退火模拟含油饱和度
(100次模拟均值图)
(二) 能够表征统计结构特征的随机算法
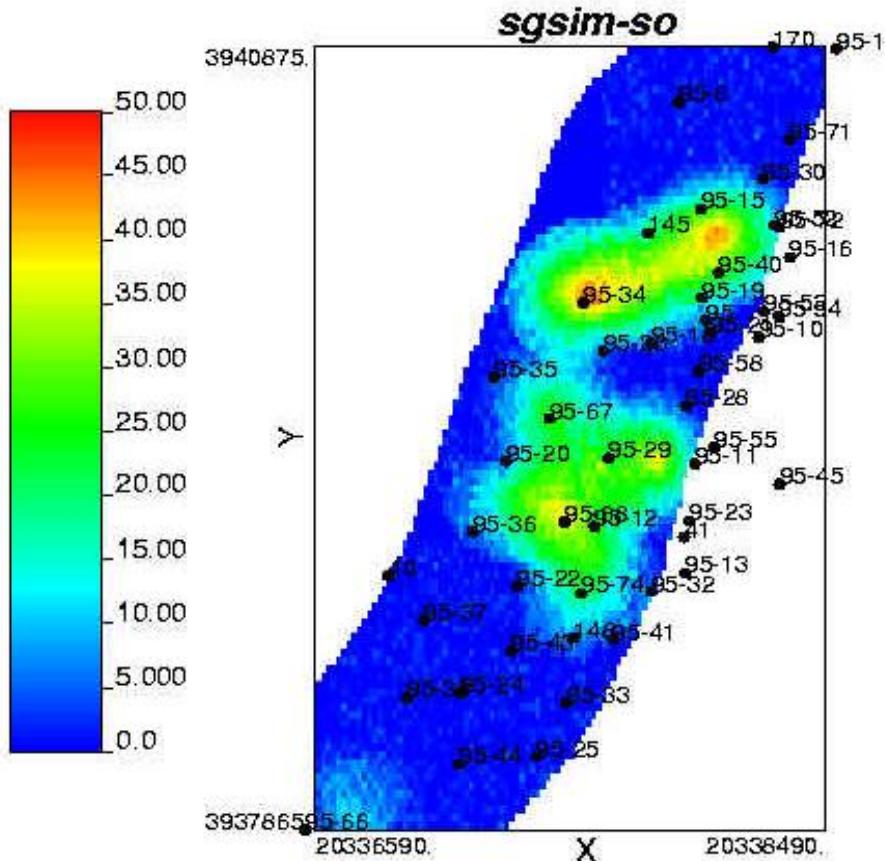
文95块55流动单元序贯高斯模拟含油饱和度
(100次模拟均值图)
二、随机建模方法
(二) 能够表征统计结构特征的随机算法
(3)随机模拟方法分类
$\textcircled{3}$ 混合模型
离散模型更接近于地质师对储层的解释,也更适合于模拟大规模的非均质性和储层不连续性。连续模型则适合于描述岩石特征的空间分布,但却或多或少采取了假设为稳定的形式。
大多数离散模型和连续模型可以以一种混合的方法进行结合。
第一步,用—个离散模型描述模型中的大型非均质性。
第二步,用不同的连续模型描述离散模型中各单元内的岩石物理参数的空间变化。
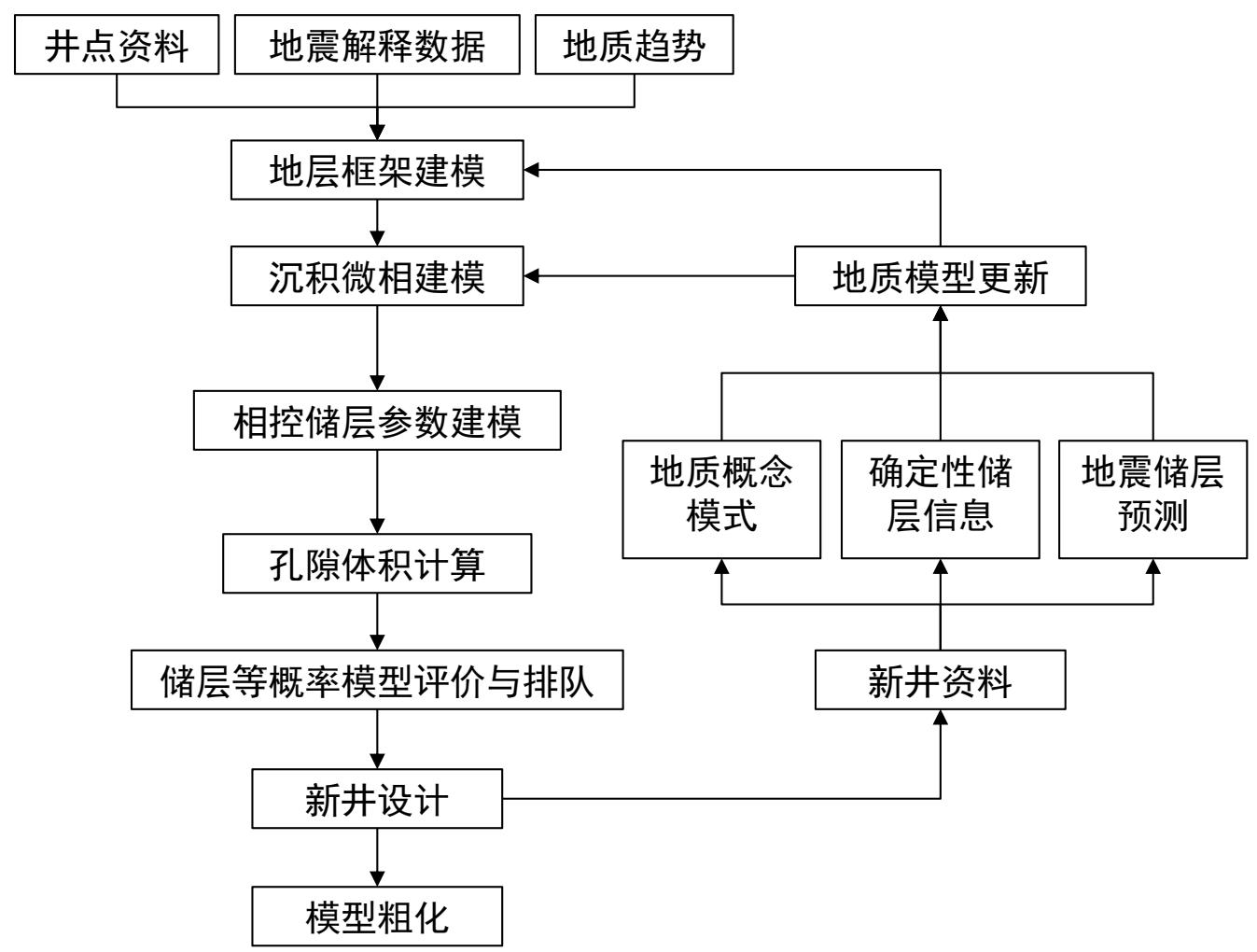
碳储地质三维建模流程图
1.数据准备
数据来源:岩心、测井、地震、试井、开发动态
从建模内容来看,基本数据类型包括以下四类:坐标数据、分层数据、断层数据、储层数据
井眼储层数据:岩心分析和测井解释—硬数据,包括井内相、砂体、隔夹层、孔隙度、渗透率、含水饱和度等数据,即井模型。
地震储层数据:主要为速度、波阻抗、频率等,为储层建模的软数据。
试井(包括地层测试)储层数据:
其一为储层连通性信息,可作为储层建模的硬数据,
其二为储层参数数据,因其为井筒周围一定范围内的渗透率平均值,精度相对较低,一般作为储层建模的软数据
(2)数据集成及质量检查
数据集成是多学科综合一体化储层表征和建模的重要前提。集成各种不同比例尺、不同来源的数据(井数据、地震数据、试井数据、二维图形数据等),形成统一的储层建模数据库,以便于综合利用各种资料对储层进行一体化分析和建模。
对不同来源的数据进行质量检查亦是储层建模的十分重要的环节。为了提高储层建模精度,必须尽量保证用于建模的原始数据特别是硬数据的准确可靠性,而应用错误的原始数据进行建模不可能得到符合地质实际的储层模型。
2.构造模型
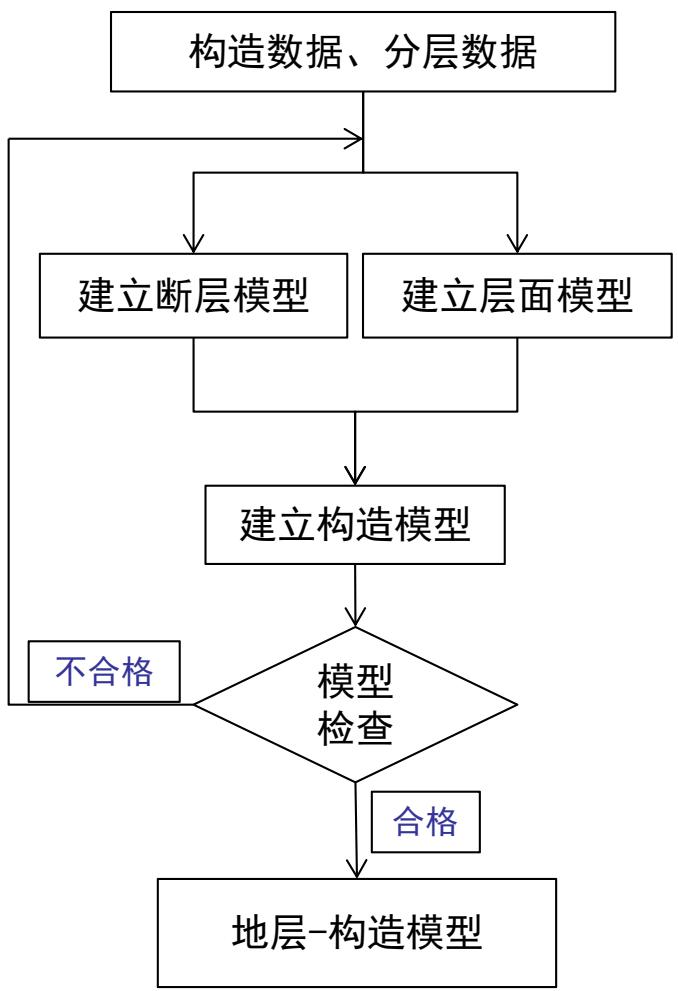
地层-构造模型建模流程
构造模型反映储层的空间格架,由断层模型和层面模型组成。
从建模软件上通过以下几个步骤实现构造模型的建立:
断层模型、三维网格化、地质层格架建模、时深转换、地层结构建模、层细剖分模型。
地层层面控制了所模拟的地质体在空间的位置,断层模型控制了工区内各断块的边界及配置关系。
构造模型主要依靠井点资料和地震解释成果,通过井点的分层资料和井间地层的对比,就可以比较好的控制该区构造形态及断层发育情况。
第3节 碳储地质建模工作流程
2.构造模型
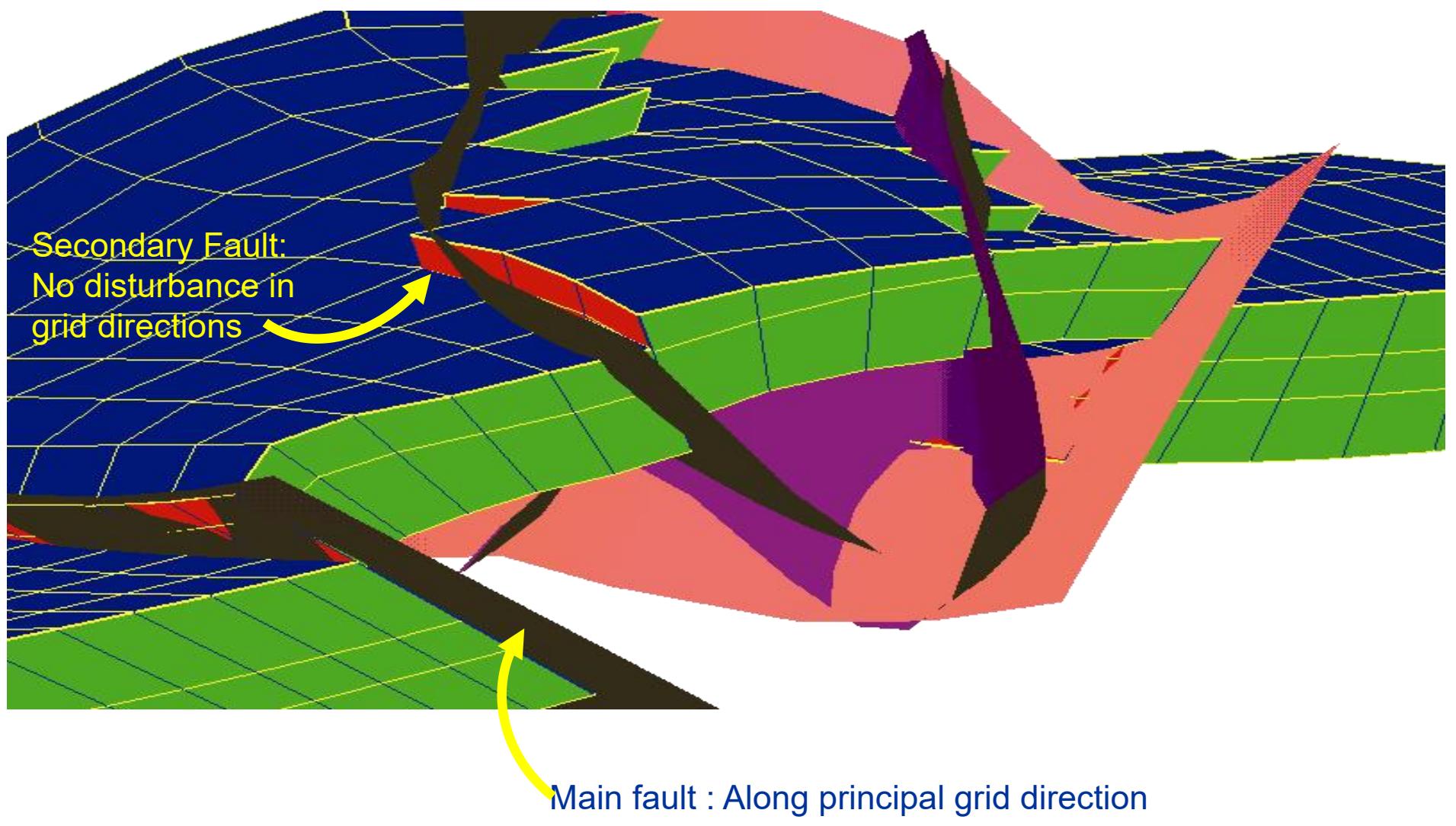
断层模型
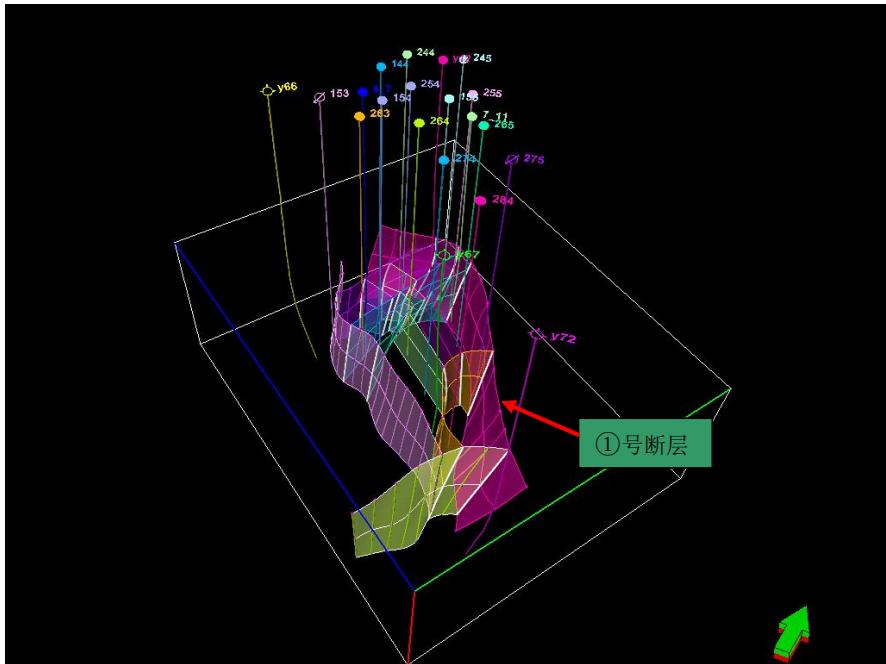
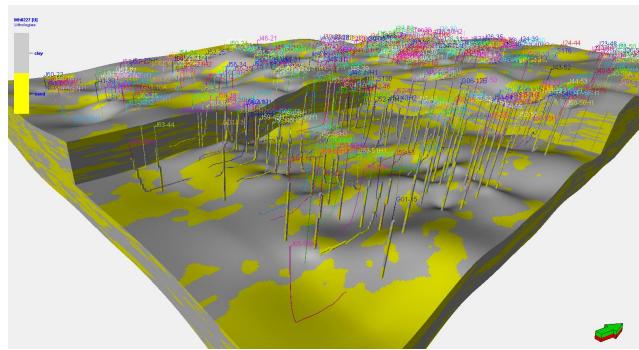
某碳圈闭断层模型
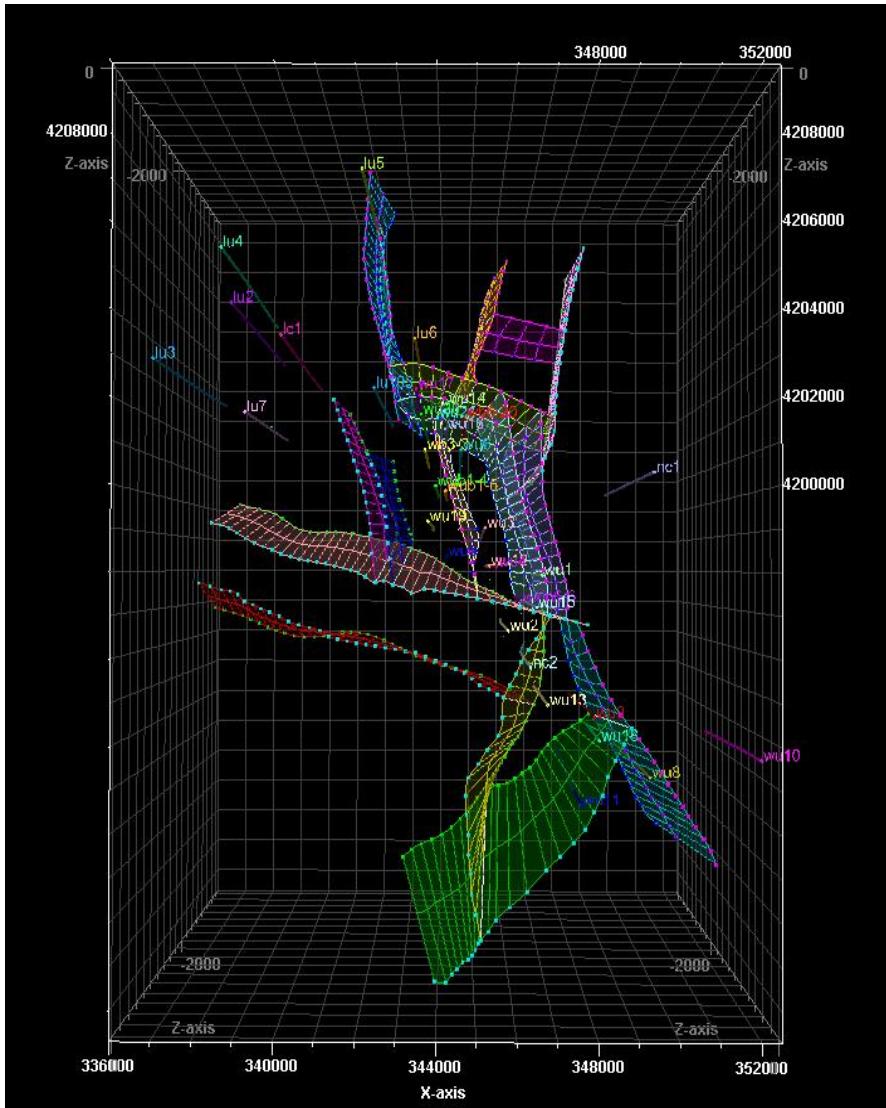
某碳储断层模型
2.构造模型
地层叠置型式
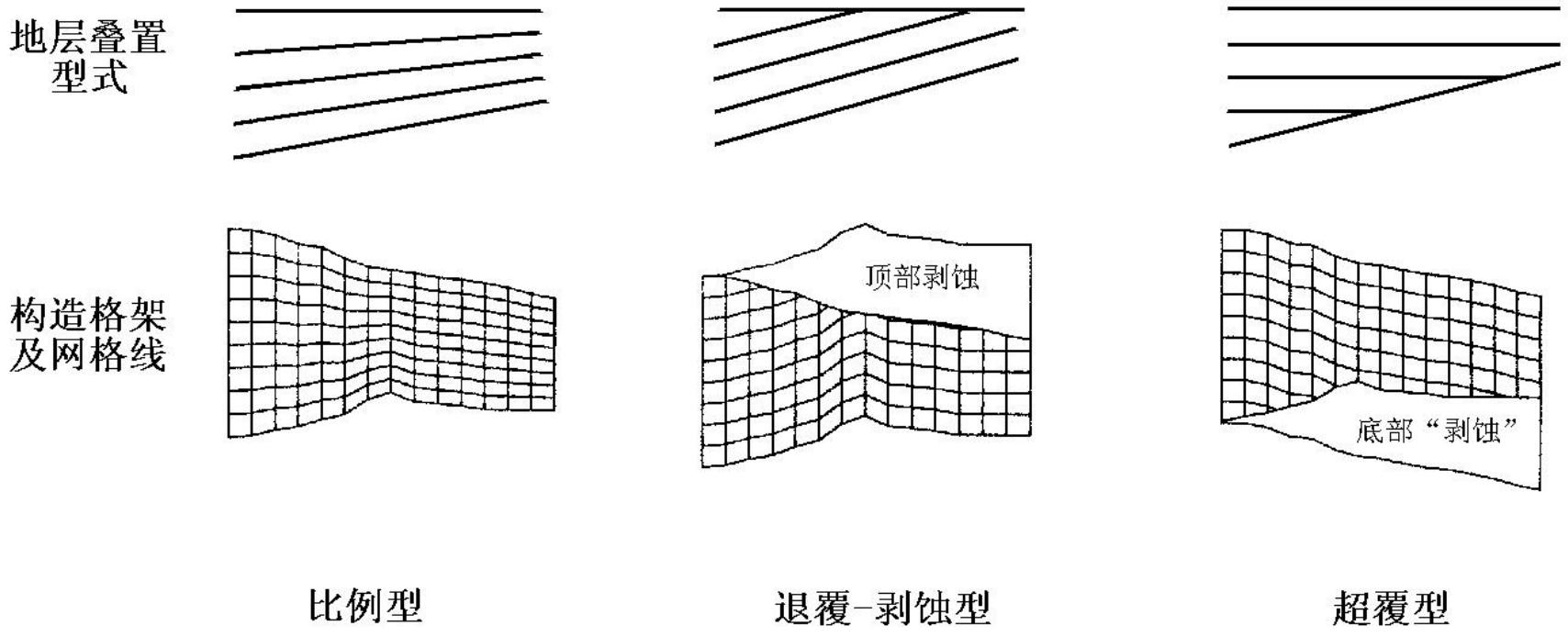
比例型:内部层面与顶、底面平行;
退覆-剥蚀型:内部层面与底面平行,而与顶面呈锐角相交;
超覆型:内部层面与底面呈锐角相交,而与顶面平行。
第3节 碳储地质建模工作流程
2.构造模型
构造模型
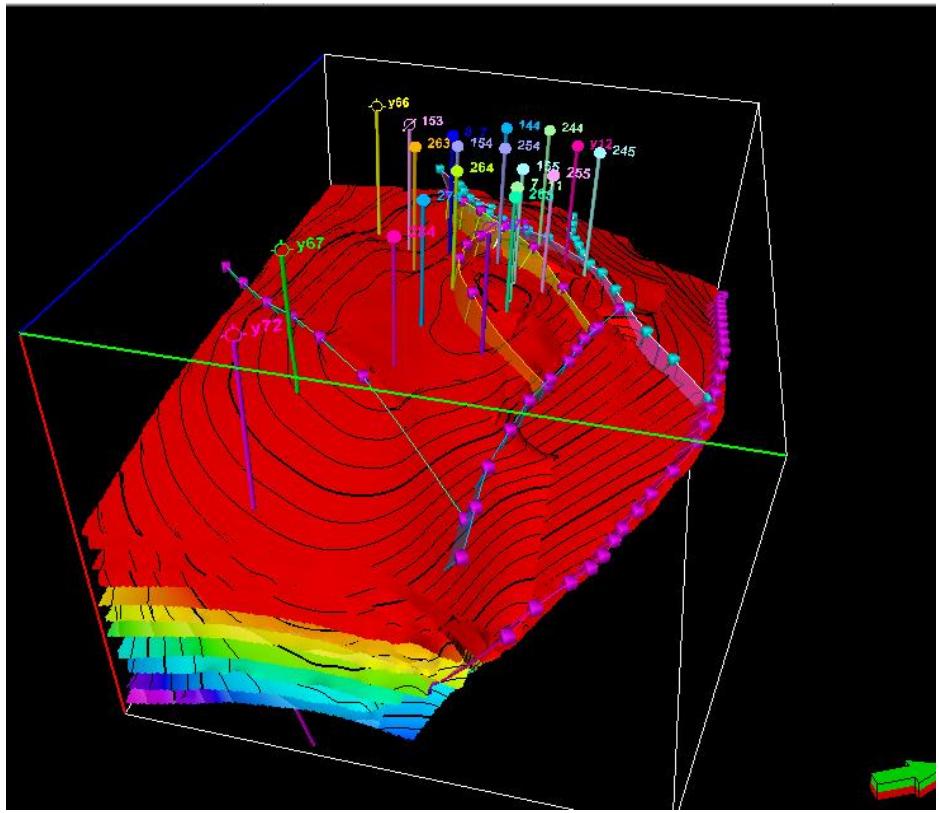
某碳圈闭断层和层面构造特征
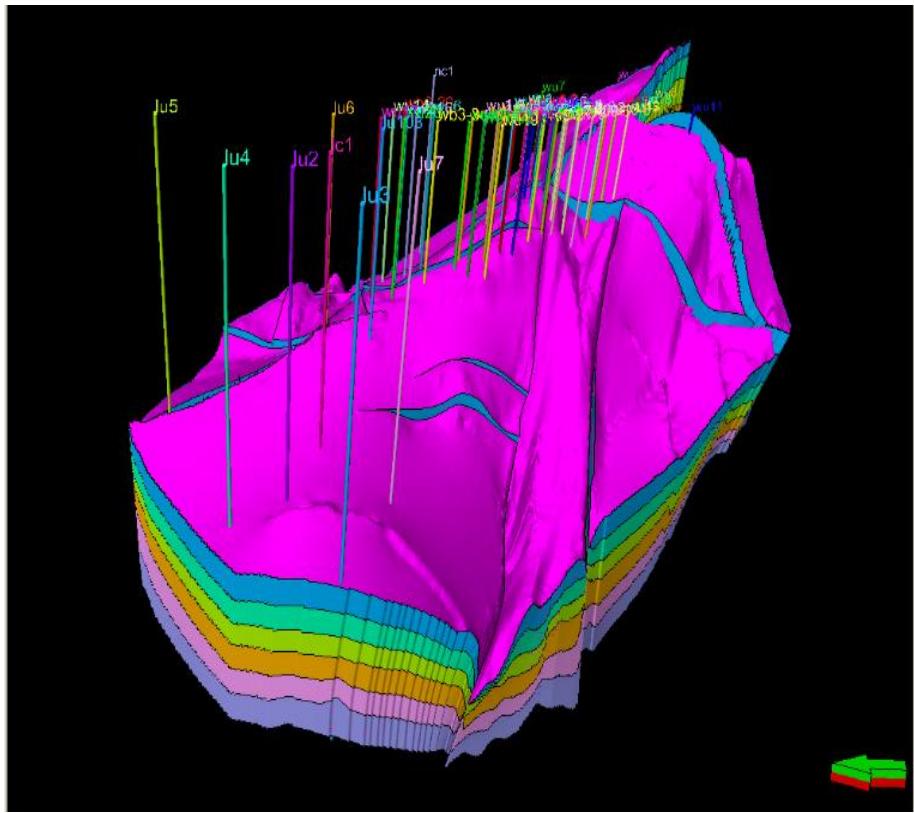
某碳圈闭断层和层面构造特征
3.沉积微相模型
第3节 碳储地质建模工作流程
3.1 赋值法建立沉积微相模型
沉积相的分布是有其内在规律的。相的空间分布与层序地层之间、相与相之间、相内部的沉积层之间均有一定的成因关系,因此,相建模对属性建模影响很大。
目前计算机所作的相图还不能替代手工制作的,一些已成熟的沉积相研究成果通过数字化加入到软件平台中。
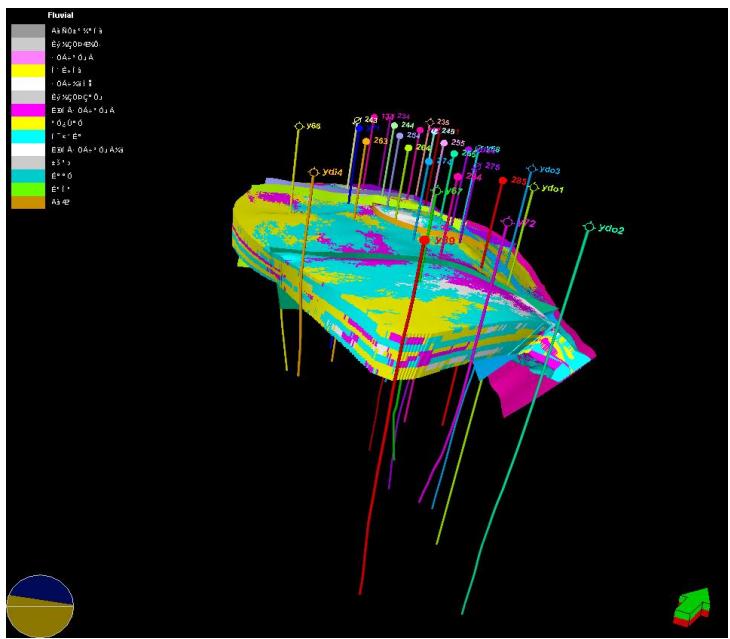
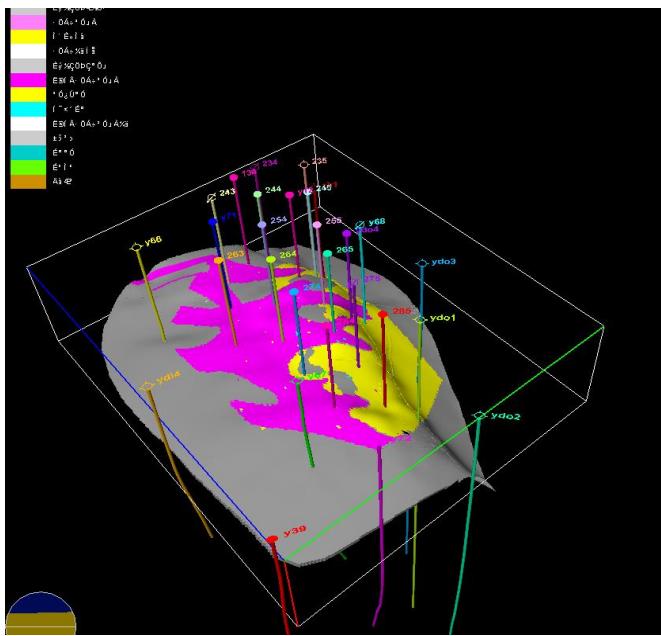
3.2 多点地质统计法建岩相模型
多点地质统计模拟
n2D训练图像
n3D训练图像
n垂向趋势变换
n多维度训练图像融合
n属性体约束
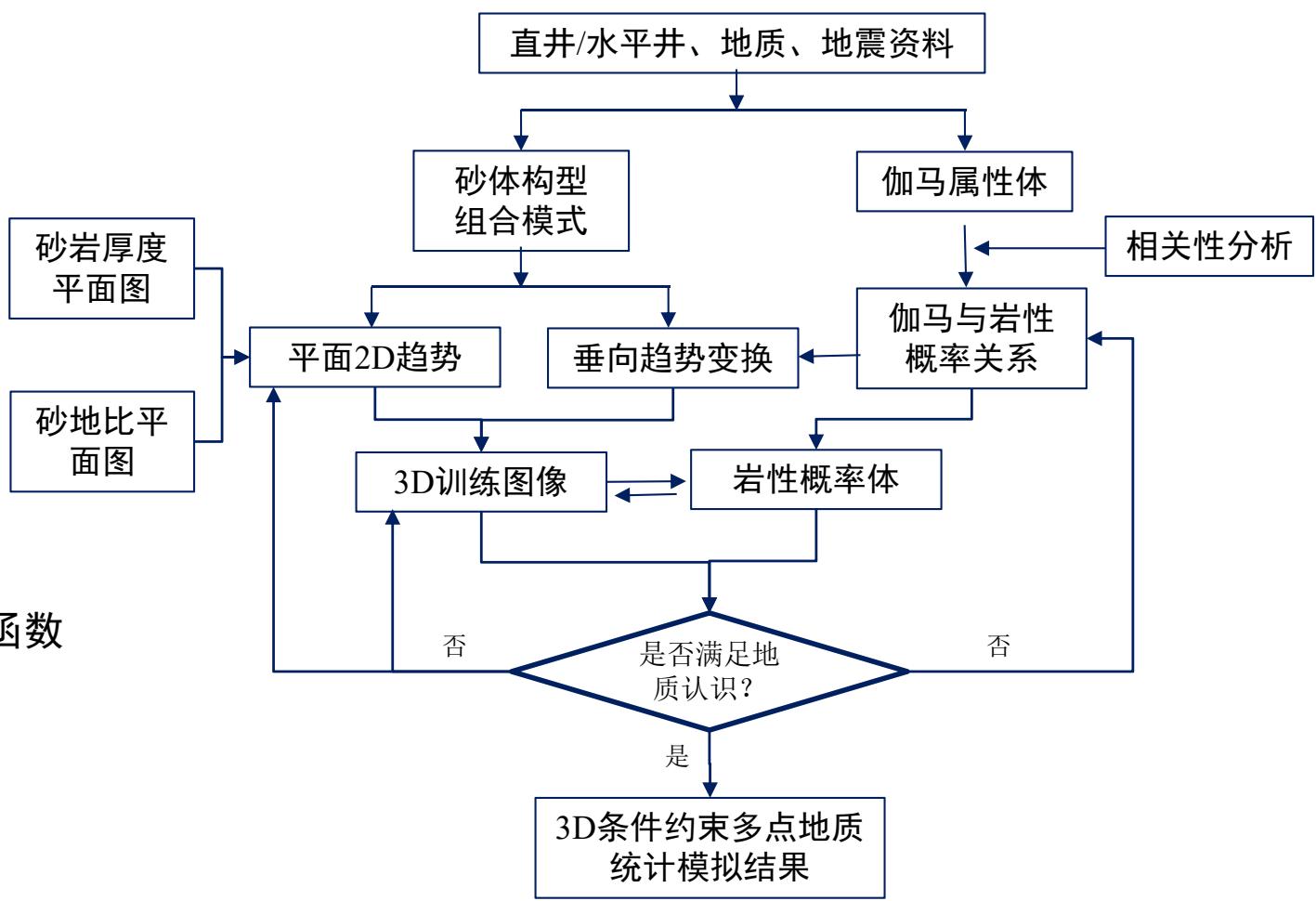
利用训练图像替代变差函进行模式引导
3.2 多点地质统计法建岩相模型
训练图像建立方法
表1训练图像建立方法对比
Table1Comparisonofestablishment methodsfortrainingimage
3.2 多点地质统计法建岩相模型
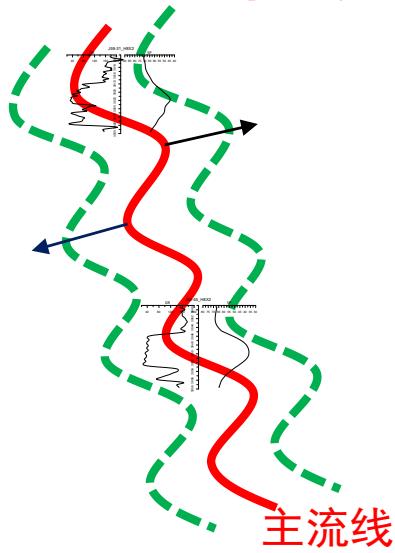
基于地质勾勒河道/主流线展布模式
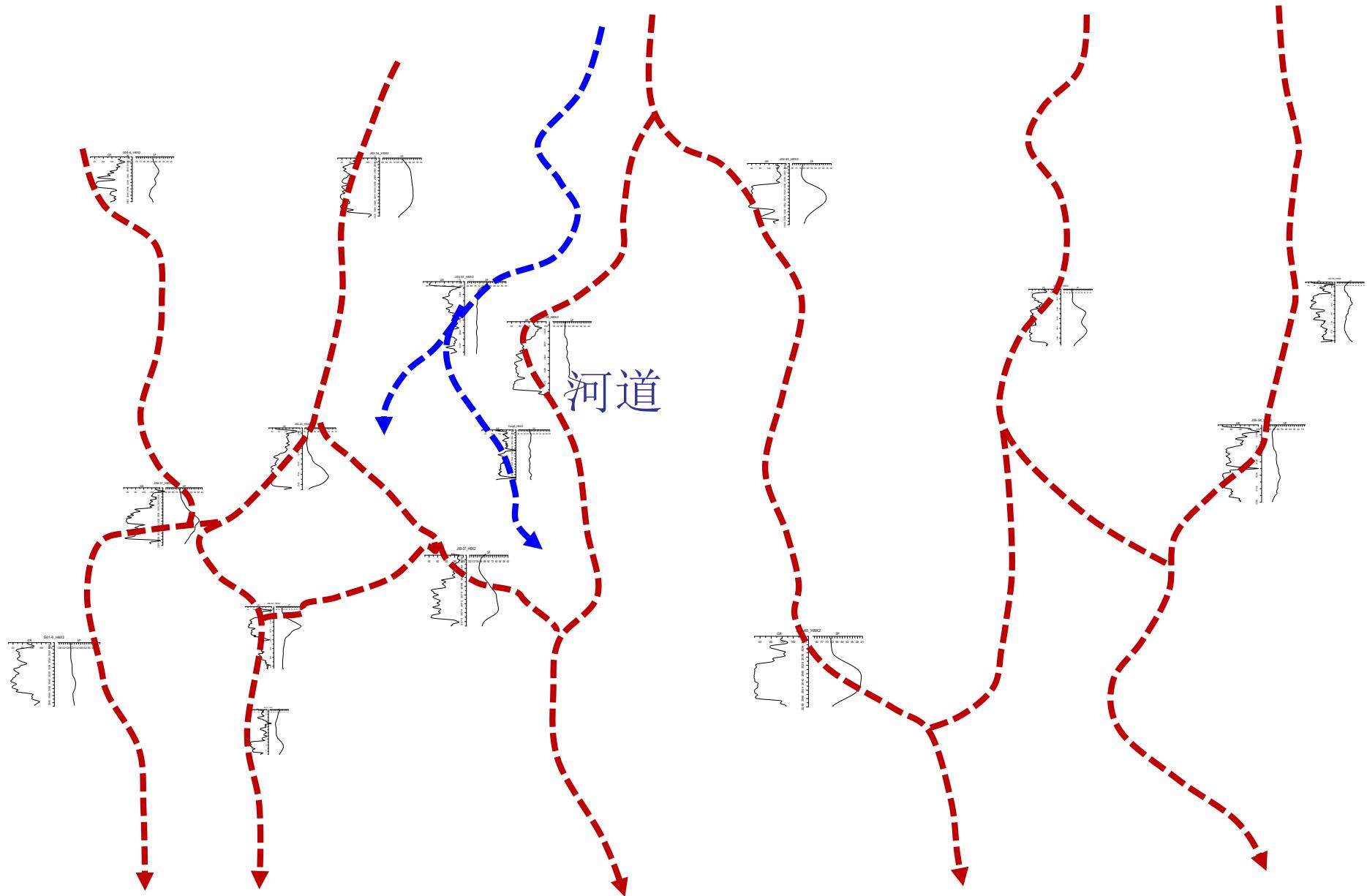
3.2 多点地质统计法建岩相模型
平面趋势建立
河道长度
河道宽度
河道波长
河道振幅
河道厚度
河道中心向两侧物性变差(距离函数
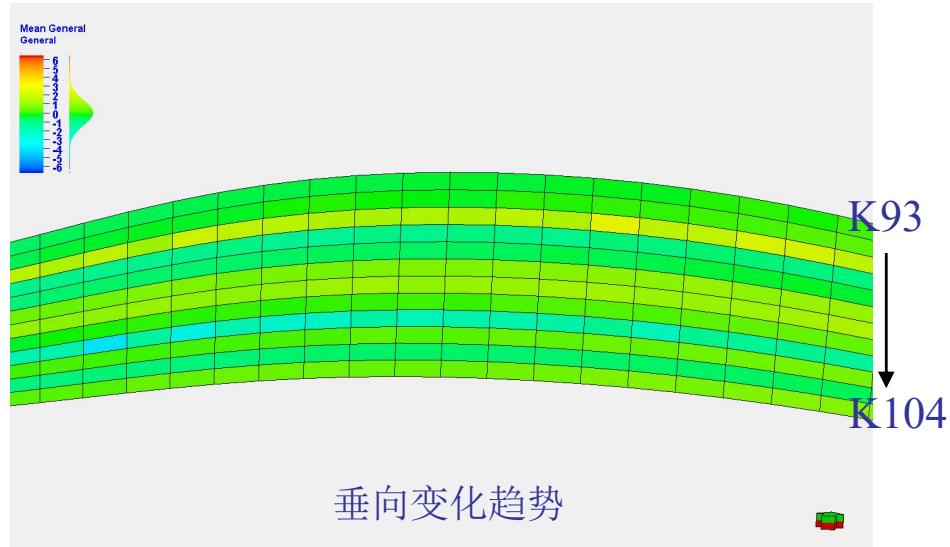
垂向变化趋势
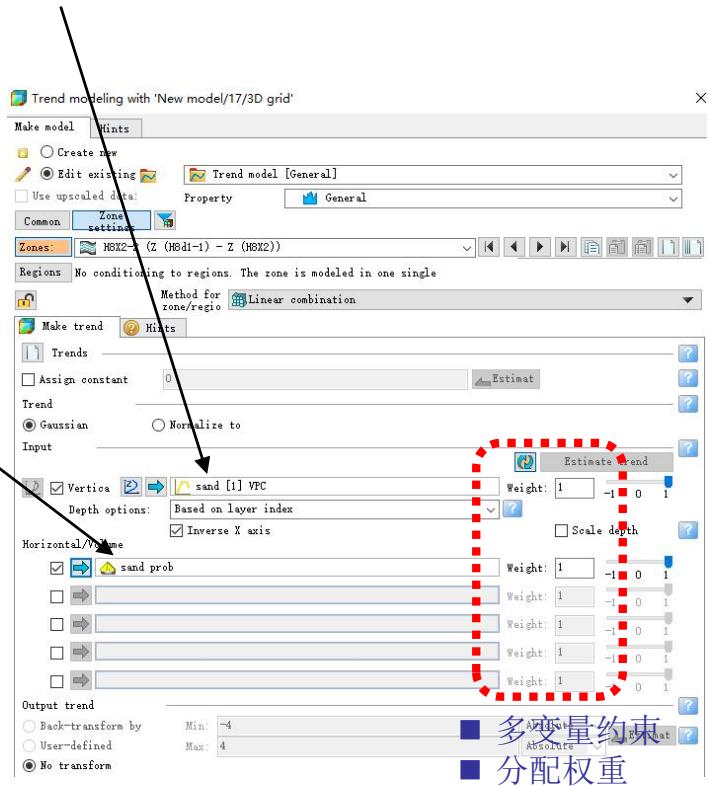
3.2 多点地质统计法建岩相模型
三维趋势建立
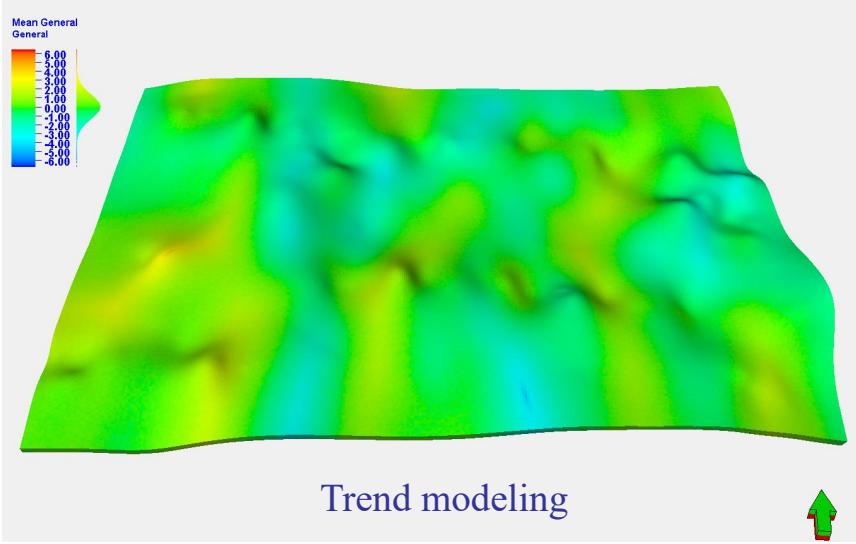
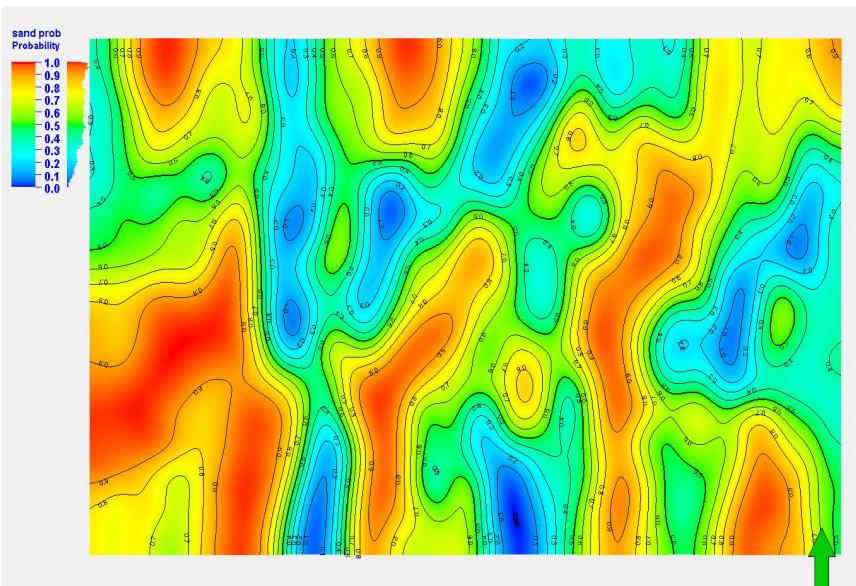
砂体平面展布趋势
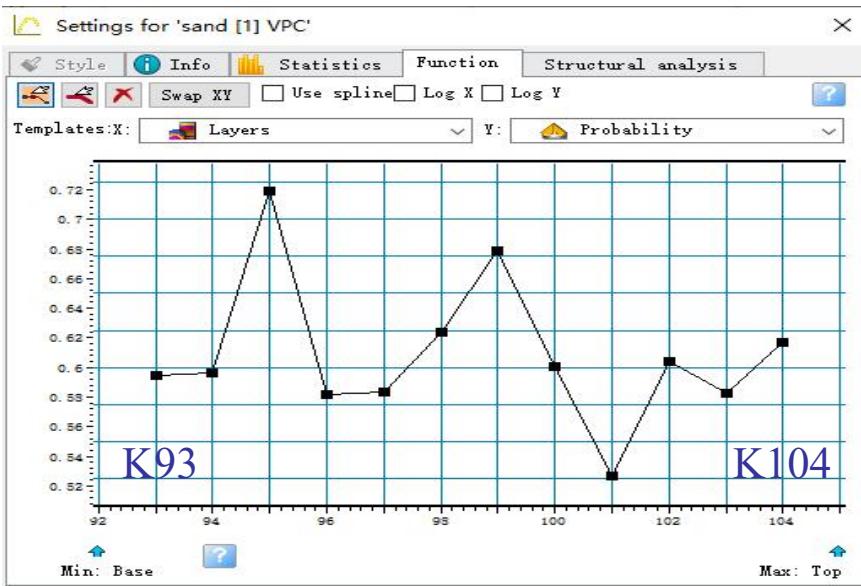
垂向变化函数
第3节 碳储地质建模工作流程
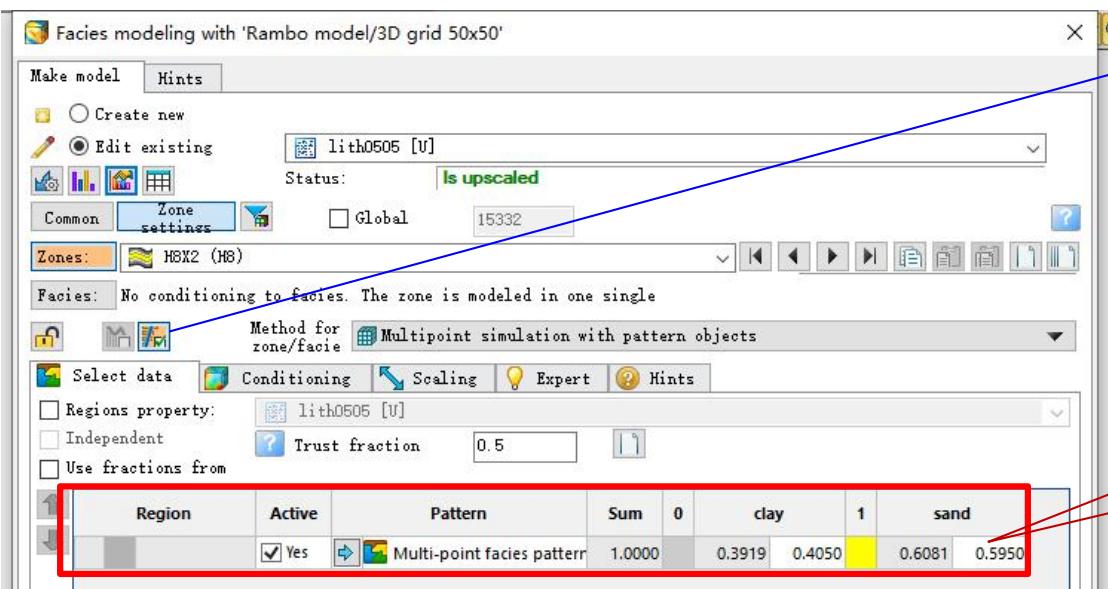
3.2 多点地质统计法建岩相模型
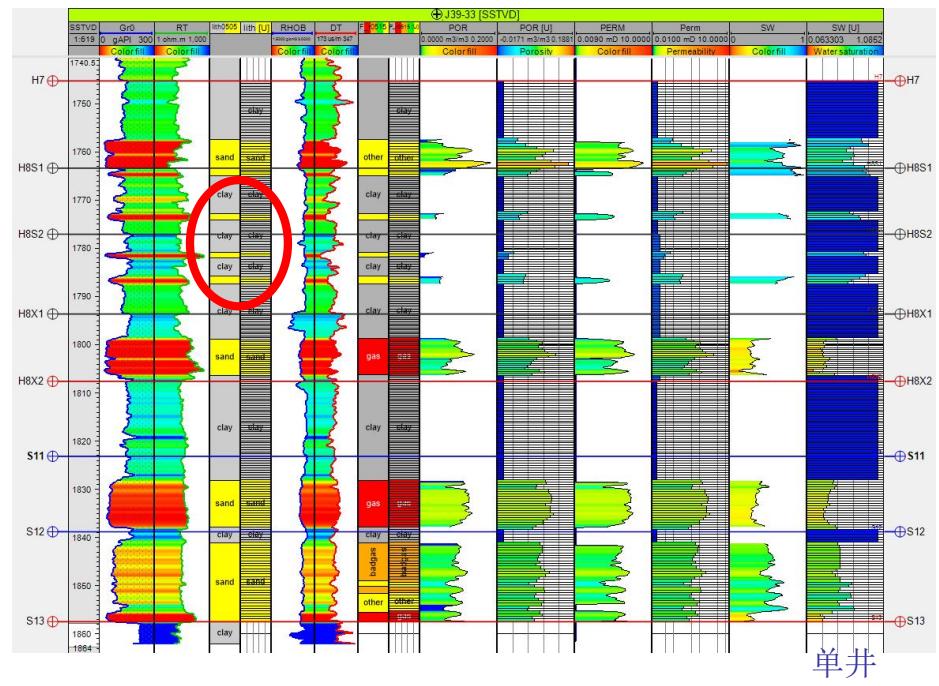
“井/体”相关性分析
垂向(沿层)趋势变换
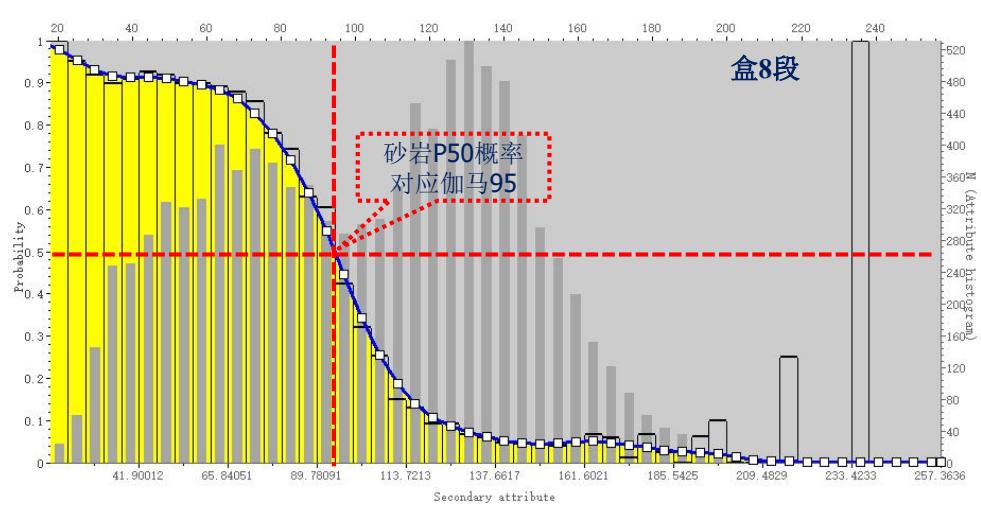
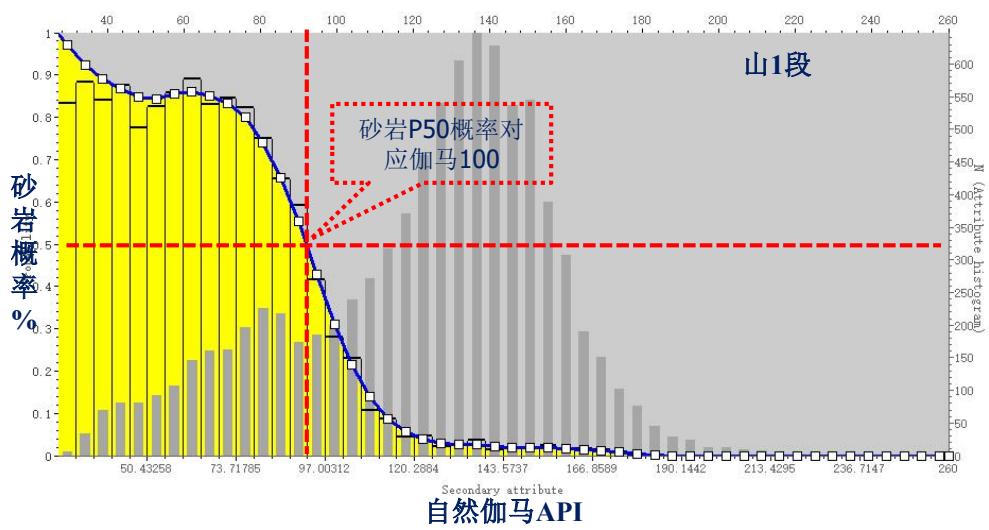
岩性与伽马相关性分析:
序贯指示模拟
概率趋势约束
多点地质统计模拟
3D训练图像
体约束
第3节 碳储地质建模工作流程
3.2 多点地质统计法建岩相模型
模拟过程
训练图像砂泥比例与井上数据误差±(10-5)%


3.2 多点地质统计法建岩相模型
岩相模型优选



根据直井与抽稀水平井模拟得到的伽马模型与采用多点地质统计学模拟岩相模型相关性较好, 平剖面一致性较好。
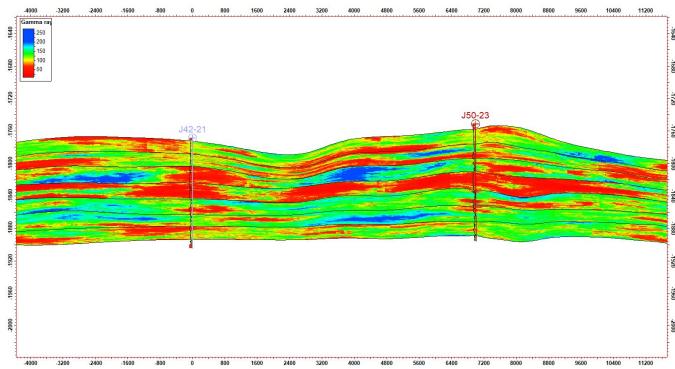
4.储层属性模型
储层属性建模流程
在构造模型基础上,建立储层属性的三维分布。
在构造模型基础上,利用井数据和/或地震数据,按照一定的插值(或模拟)方法对每个三维网块进行赋值,建立储层属性(离散和连续属性)的三维数据体,即储层属性模型。
网块尺寸越小,标志着模型越细;每个网块上参数值与实际误差愈小,标志着模型的精度愈高。
第3节 碳储地质建模工作流程
4.储层属性模型
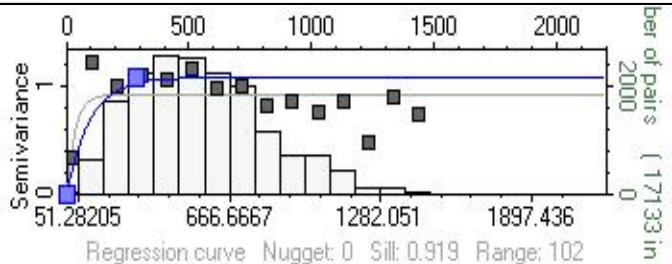
变差函数
变差函数反映储层参数的空间相关性,能否求得理想的变差函数,并将成果应用到属性模型的建立中,是随机建模工作的一个关键。
在实际建模过程中,参考地质概念模式来估计变差函数的各项参数,即根据河道发育的方位、延伸长度、河道宽度、纵向沉积单元厚度来确定主方向、主次变程。由于在纵向上有逐点解释的物性数据,因此,从实际资料中能够计算和拟合出变程、基台值,得到关于储层纵向上物性分布的结构特征。
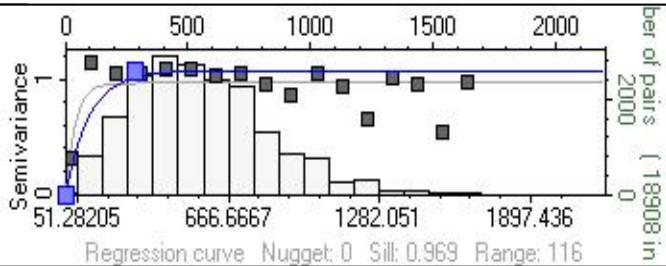
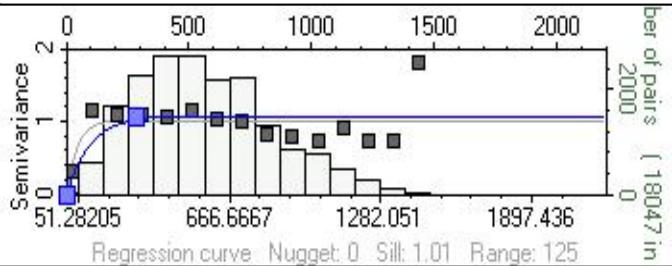
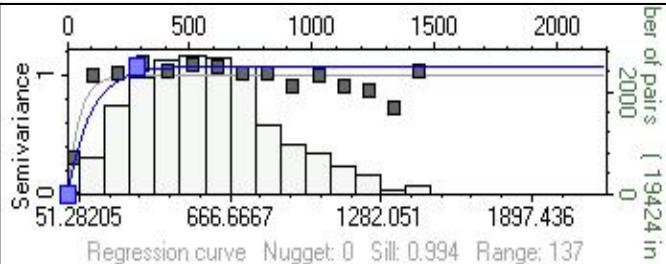
4.储层属性模型
变差函数
为了达到属性分布模拟符合岩性分布的基本规律,在具体的模拟算法上,我们尽可能使用一些地质约束,有相控条件的当然要建立沉积相模型。没有相控条件的,主要靠地质参数来约束。保证井上散点数据最大限度的保真,结合地质学家所做的相分析或者我们所做的储层模拟边界。第一步是统计各沉积微相中岩石物性的分布特征;用区域化变量的空间变差函数,来描述储层渗透率、孔隙度等参数的空间分布特征;求取各参数的实验变差函数,选择合适的理论变差模型,拟合理论变差模型的各项参数。
首先,我们得承认,井间存在不确定性,资料越少,不确定性就越大。不是通过插值就能得到的,地下是复杂和未知的,资料再详细,也有不确定的时候,因此地质统计无时不在,在集成所能获得的资料的情况下合理运用地质统计并不是在玩数值游戏。
第3节 碳储地质建模工作流程
4.储层属性模型
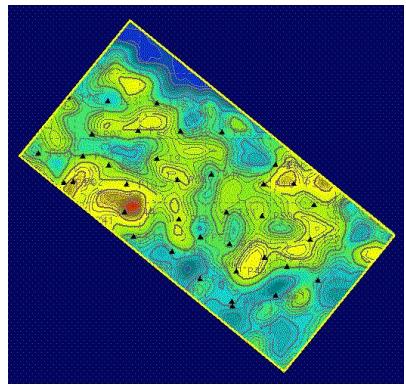
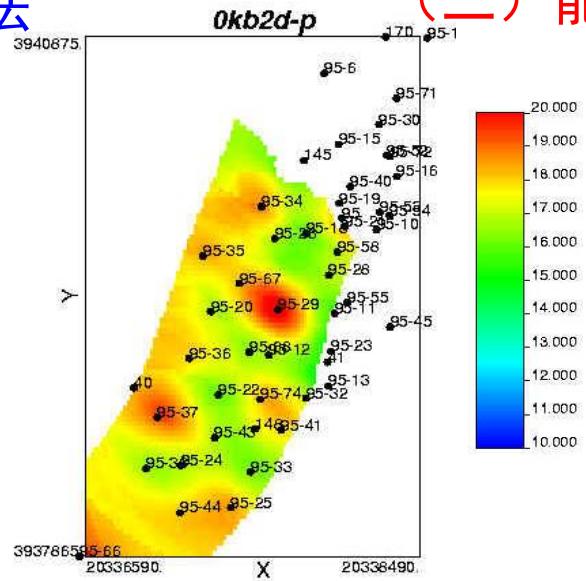
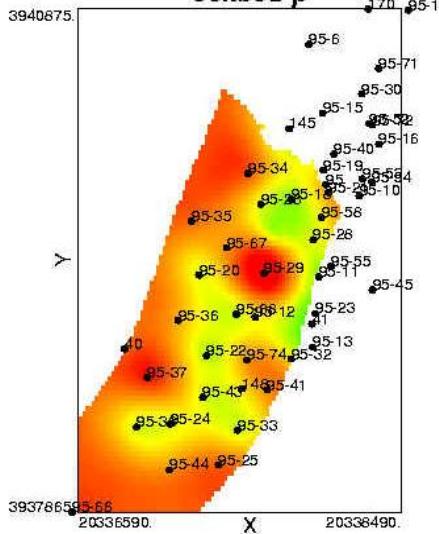
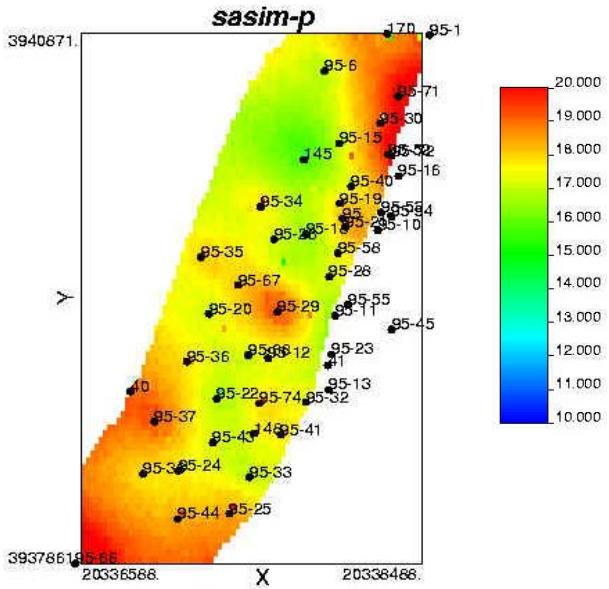
属性模型

某碳储孔隙度三维分布模型
第3节 碳储地质建模工作流程
4.储层属性模型
属性模型
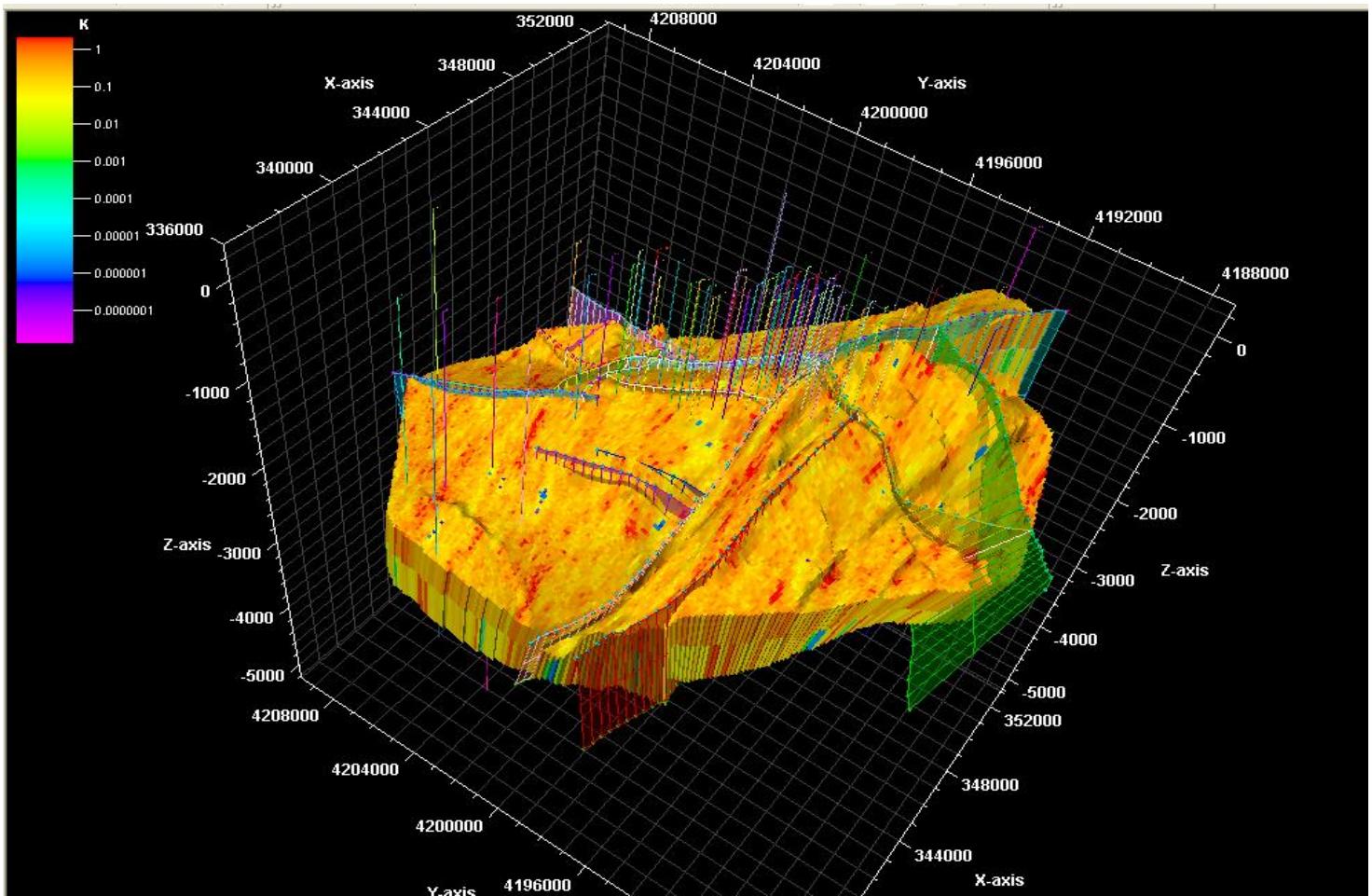
某碳储渗透率三维模型
第3节 碳储地质建模工作流程
4.储层属性模型
属性模型

某碳储含水饱和度三维模型
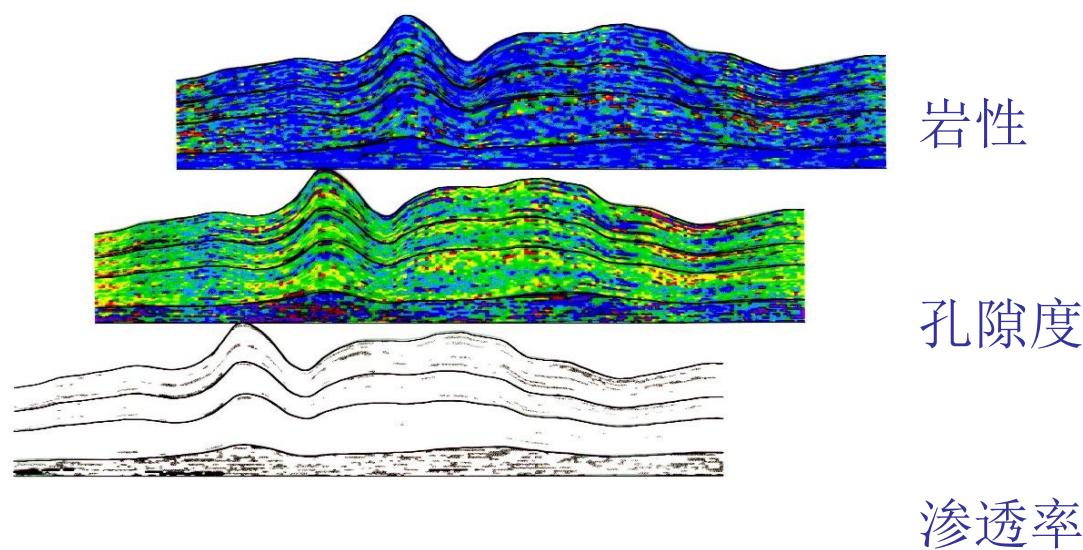
4.储层属性模型
属性模型
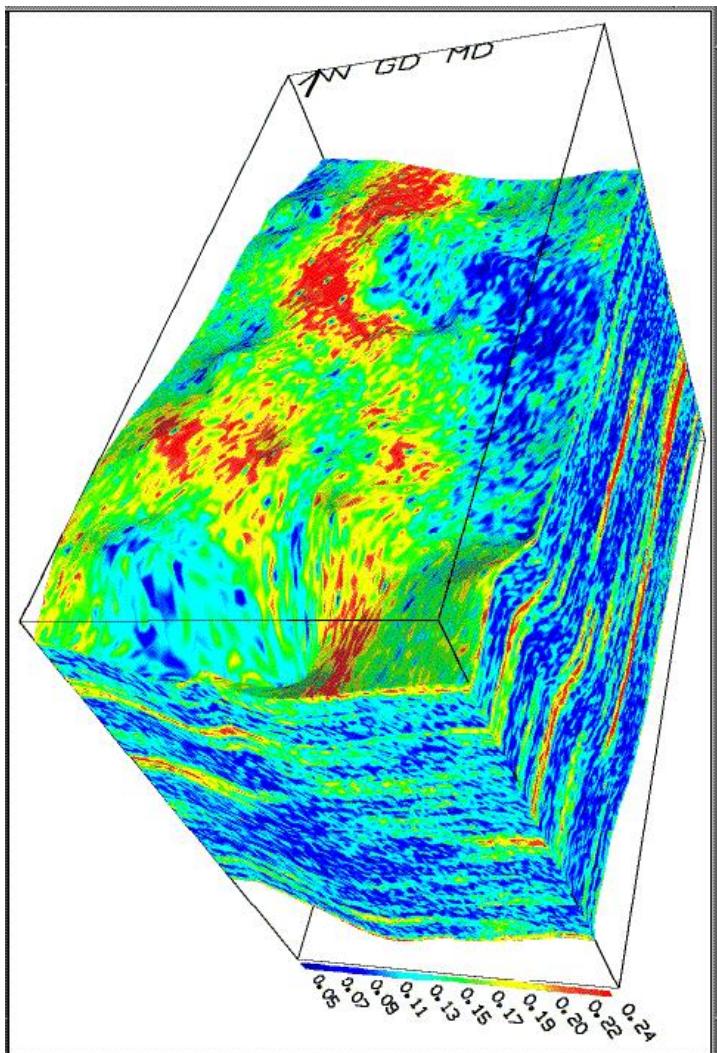
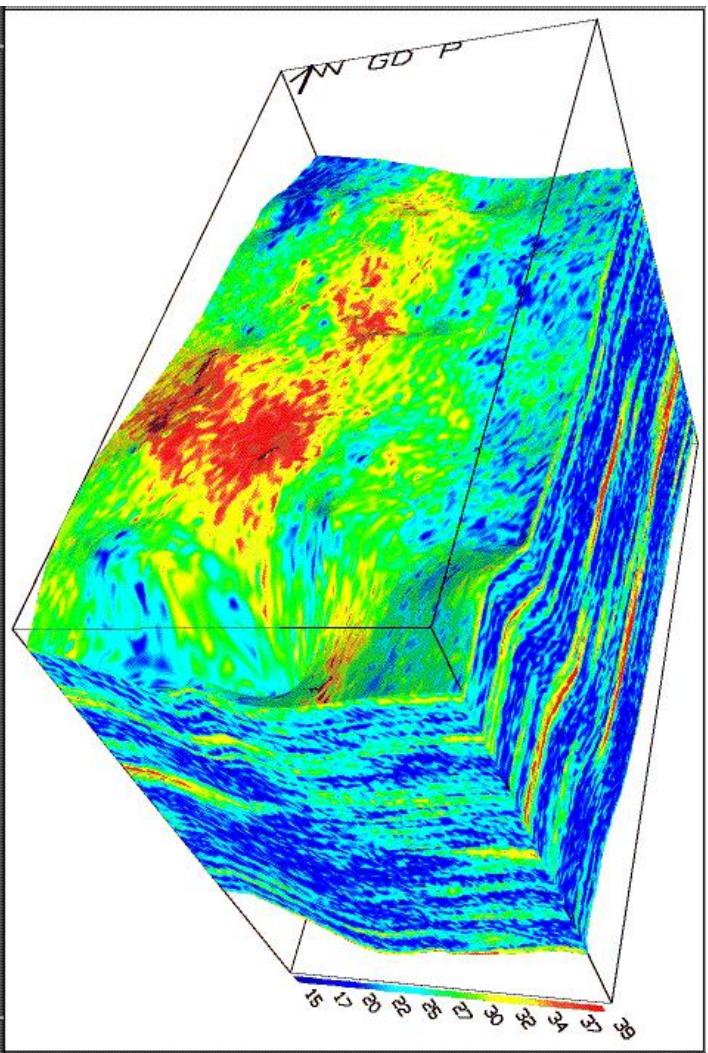
三维地质模型立体图
4.储层属性模型
属性模型
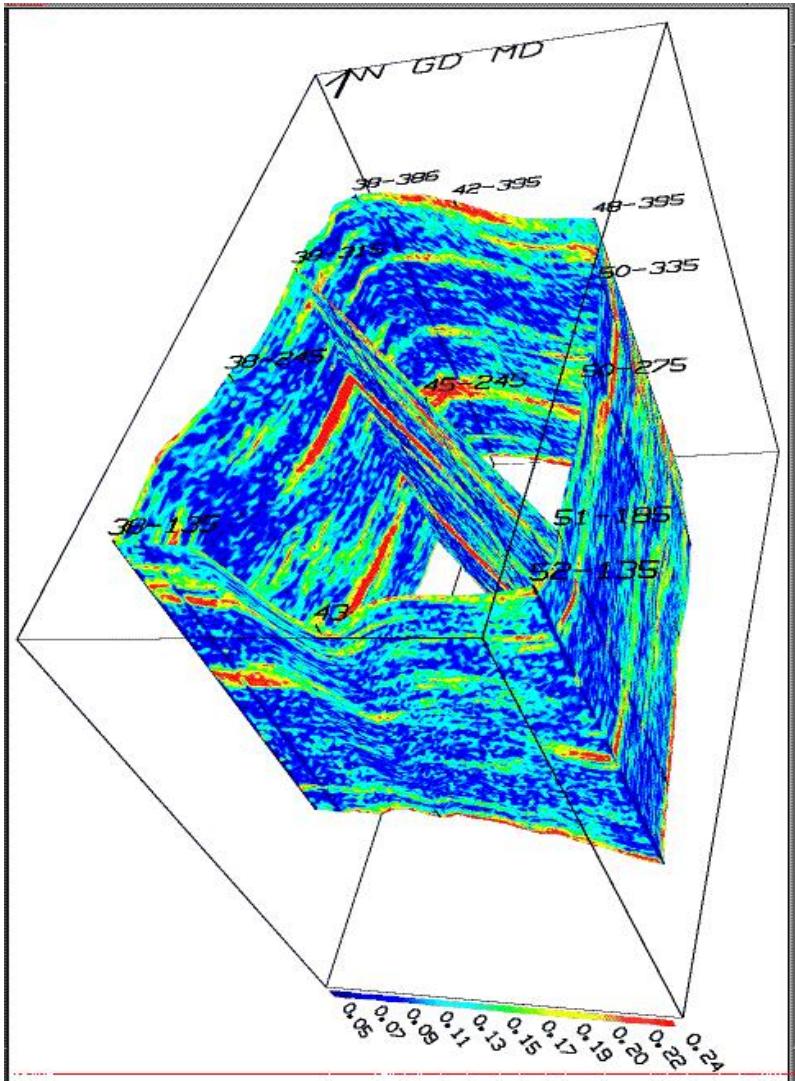
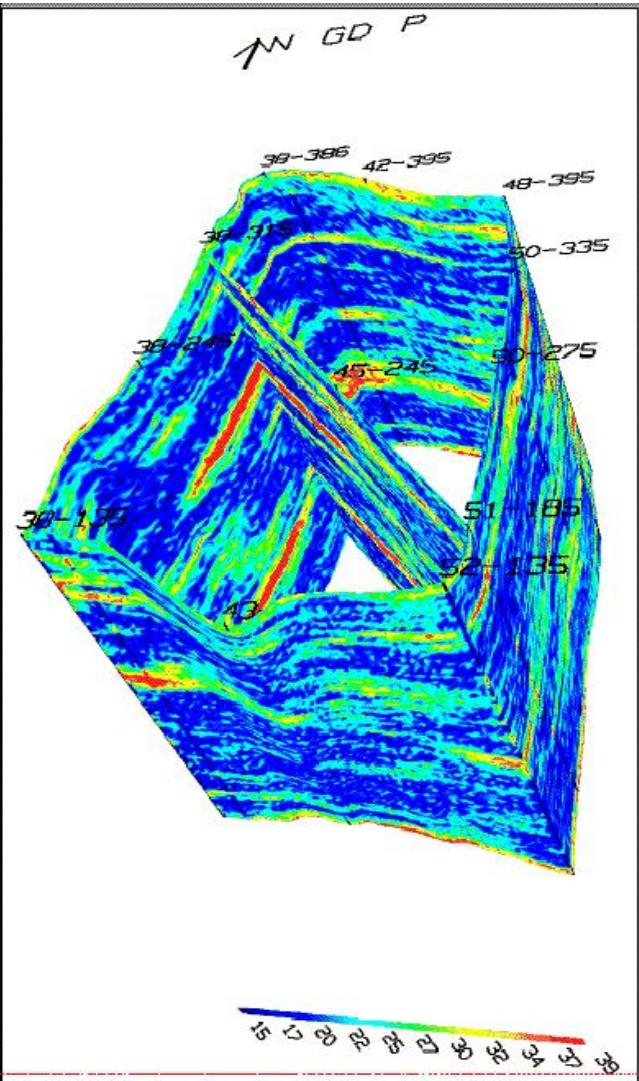
栅状剖面图
4.储层属性模型
属性模型
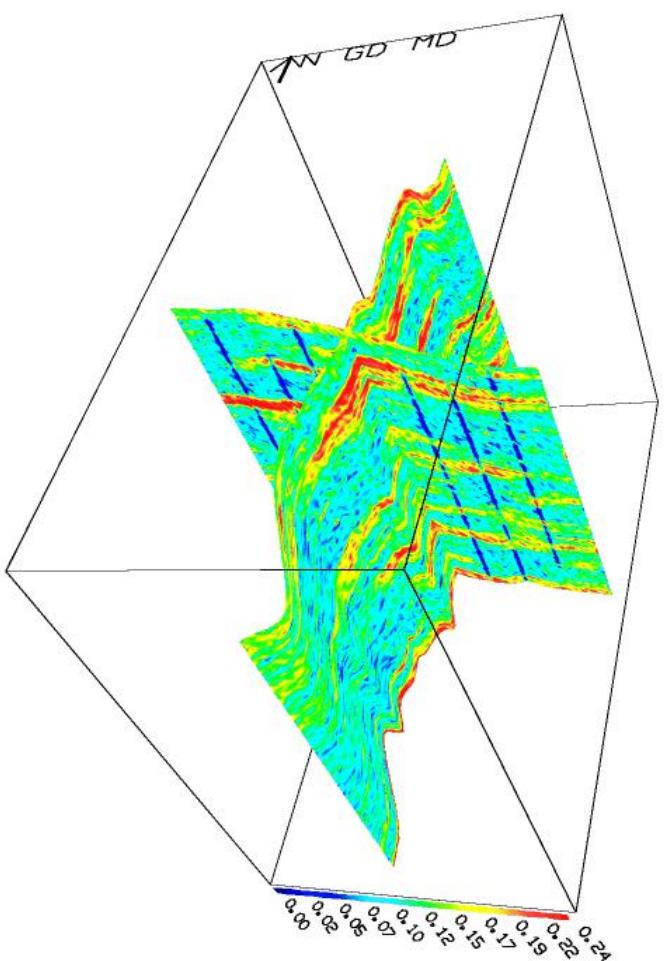
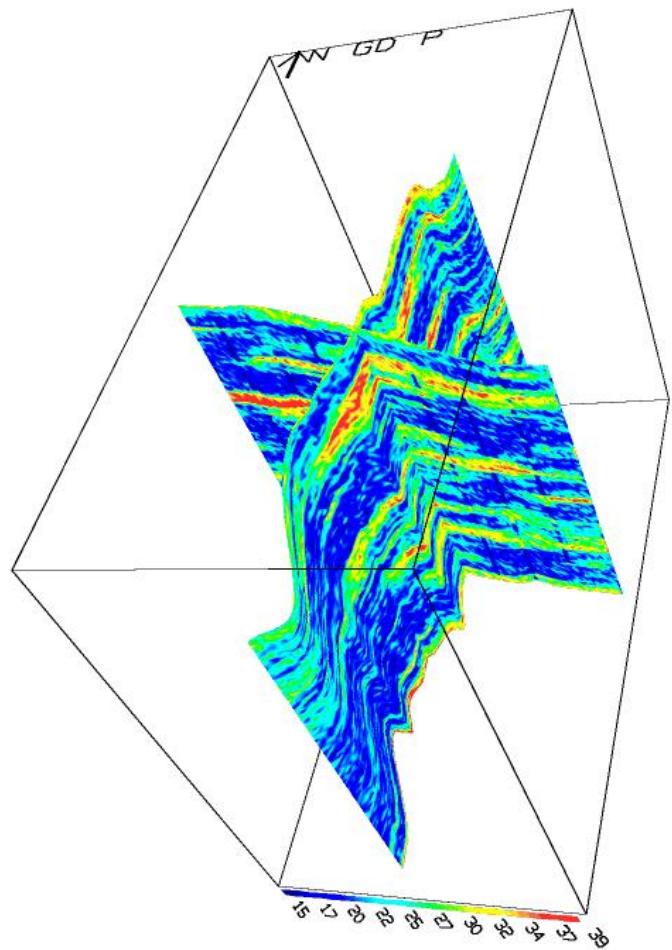
交叉剖面图
5.体积计算与模型质量检验
根据三维储层模型进行碳储容积计算。
地层总体积
储层总体积以及不同相(或流动单元)的体积
储层孔隙体积
连通体积(连通的储层岩石体积、孔隙体积)
—第j套实现的碳储容积,
—第j套实现第i个网格大小,
(?) —第j套实现第i个网格的储层厚度,m;
? —第j套实现第i个网格的储层孔隙度,小数;
—第j套实现的含有网格数;
某门槛值的显示及体积计算
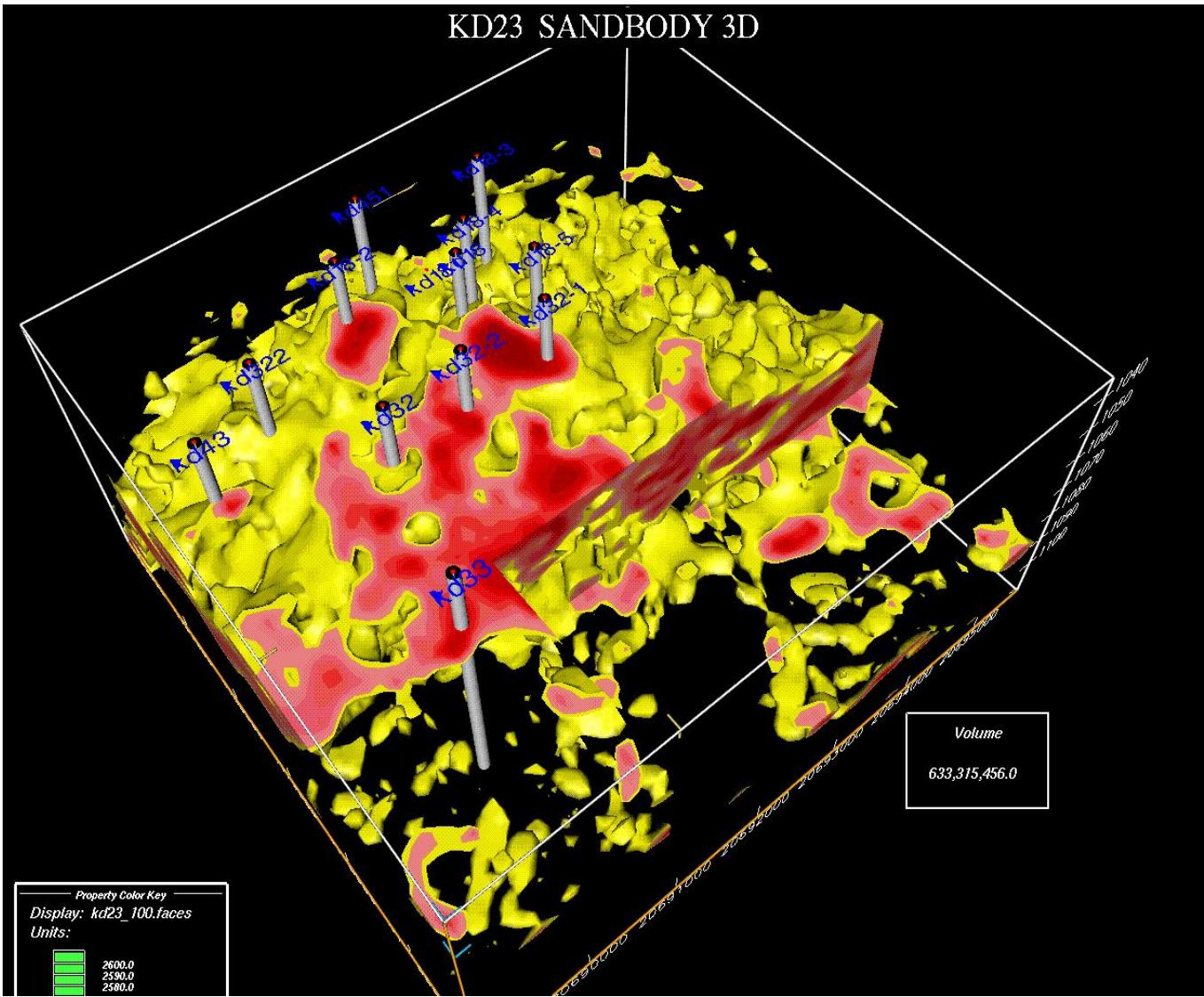
5.体积计算与模型质量检验
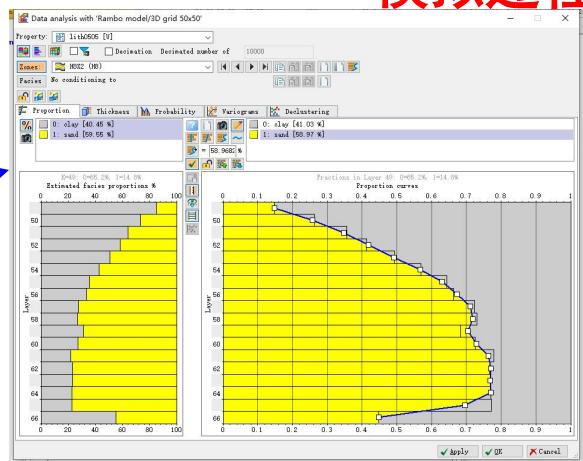
数据分析及地质统计
进行多种数据转换,描述属性在空间的分布规律。
模型检验和储量计算
应用定性法和定量法对地质模型进行检验,在确定合理的地质模型的基础上,计算储量,并与上交地质储量进行对比分析,同时进行储量评价。
模型后处理
对合理的地质模型进行网格粗化和后处理,为CCUS数值模拟提供合格的地质模型。
第3节 碳储地质建模工作流程
5.体积计算与模型质量检验
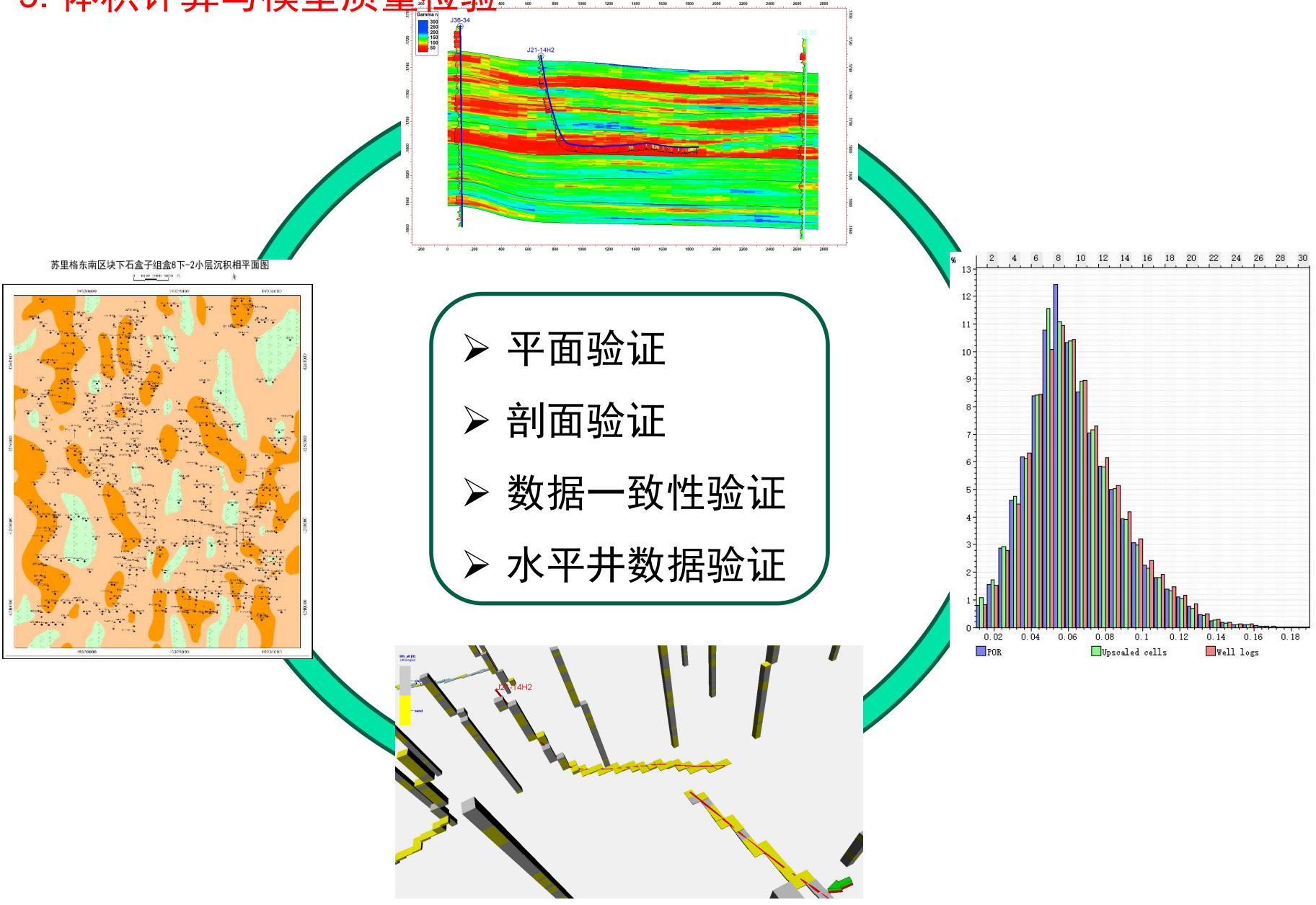
第3节 碳储地质建模工作流程
5.体积计算与模型质量检验
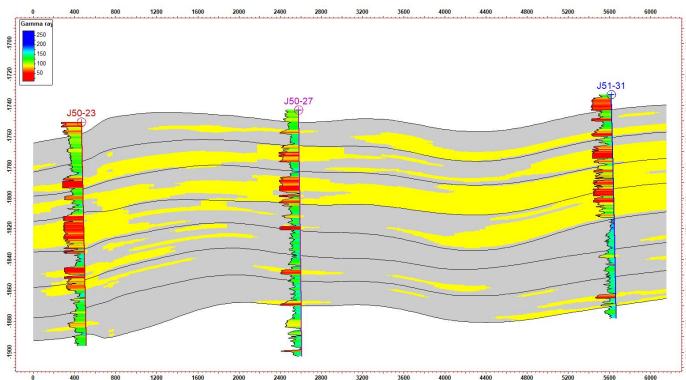
5.1 平面验证
平面(模型实现与地质概念)一致性较好

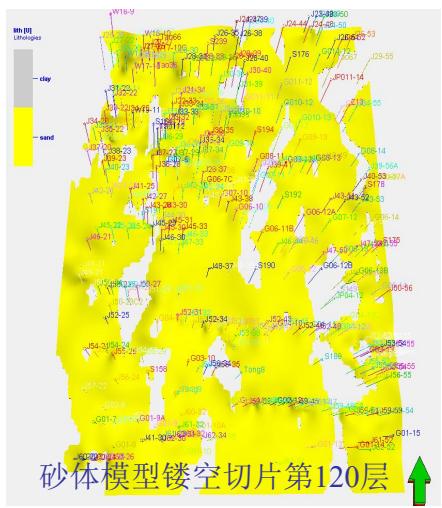


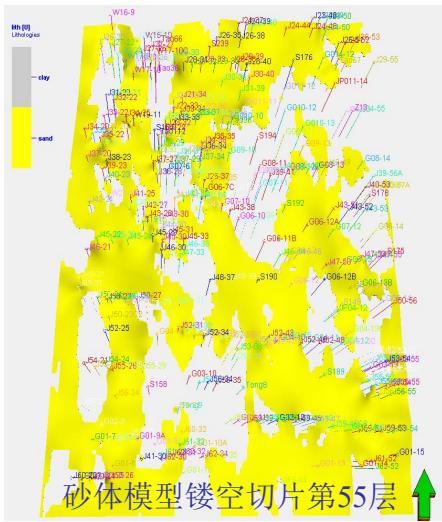

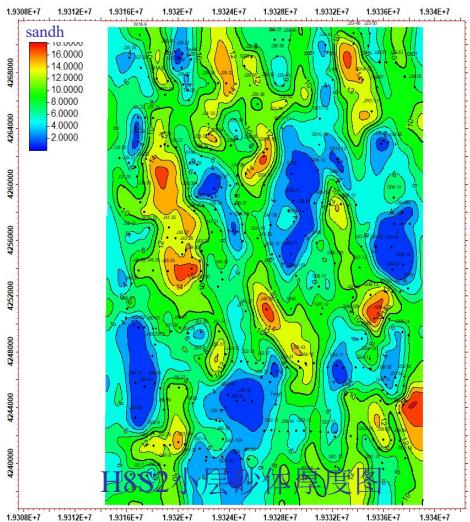
第3节 碳储地质建模工作流程
5.体积计算与模型质量检验
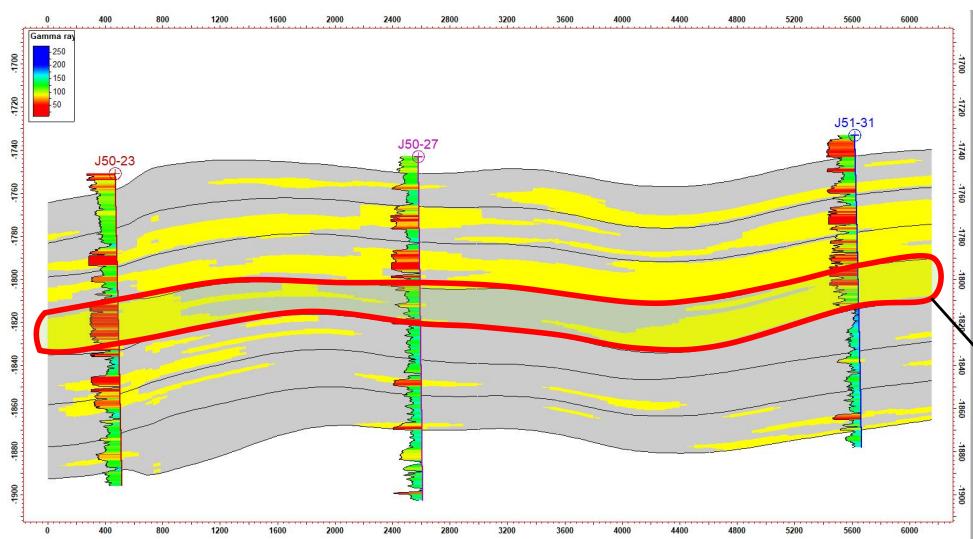
5.2 剖面验证
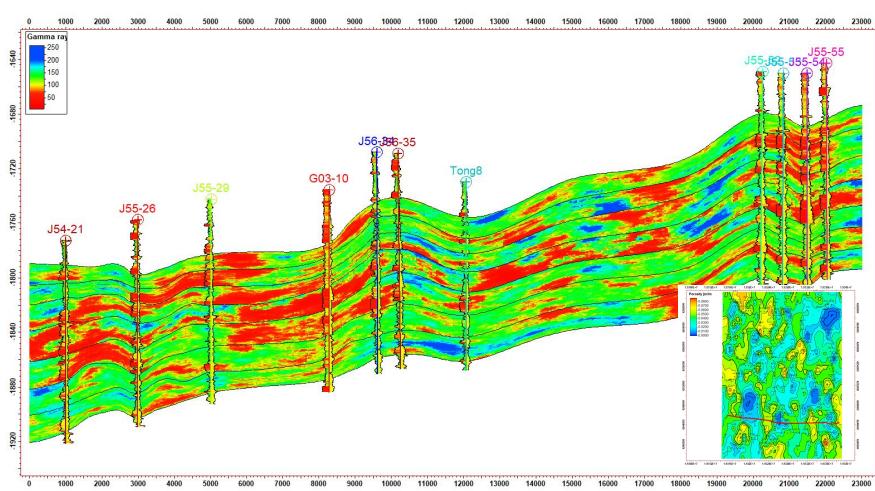

模拟结果显示:
剖面一致性较好
第3节 碳储地质建模工作流程
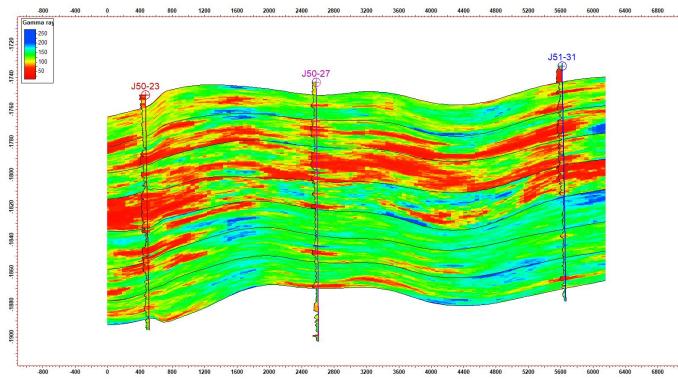
5.体积计算与模型质量检验
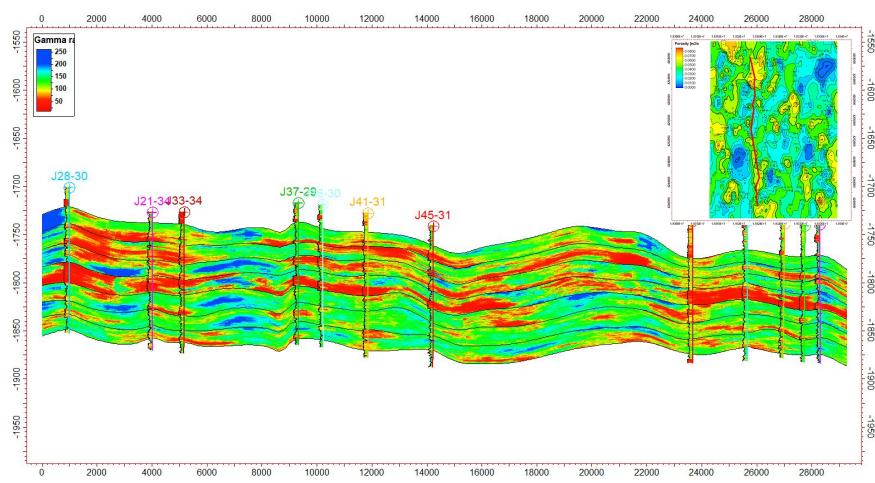
5.2 剖面验证
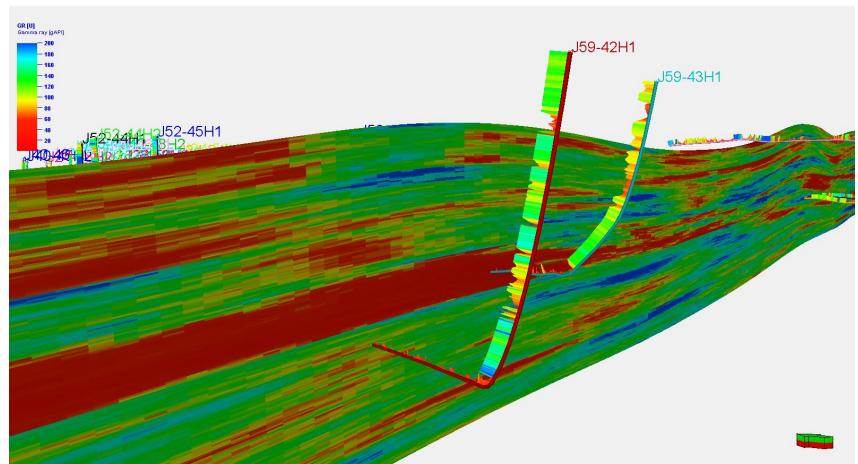
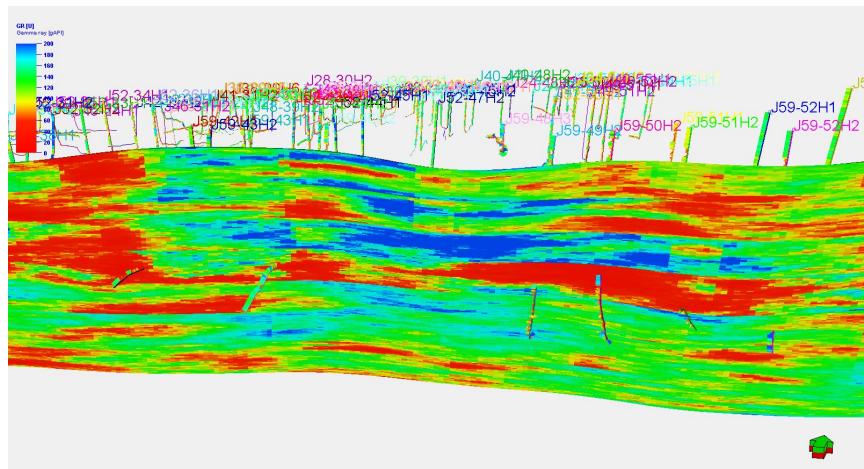
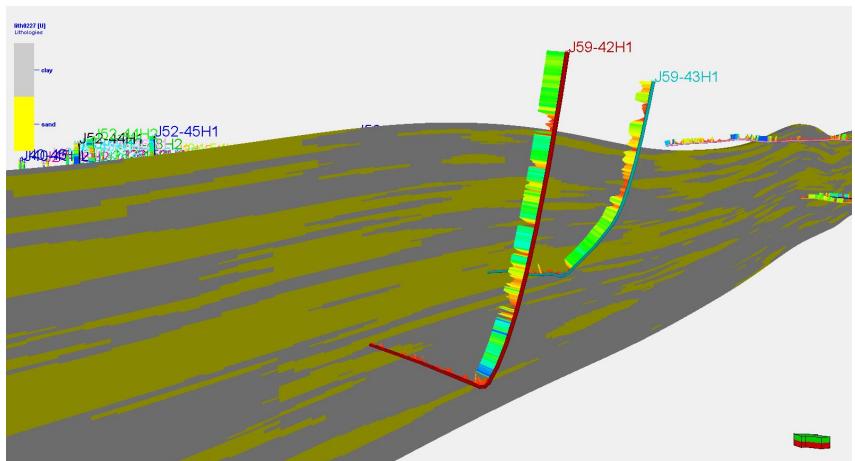
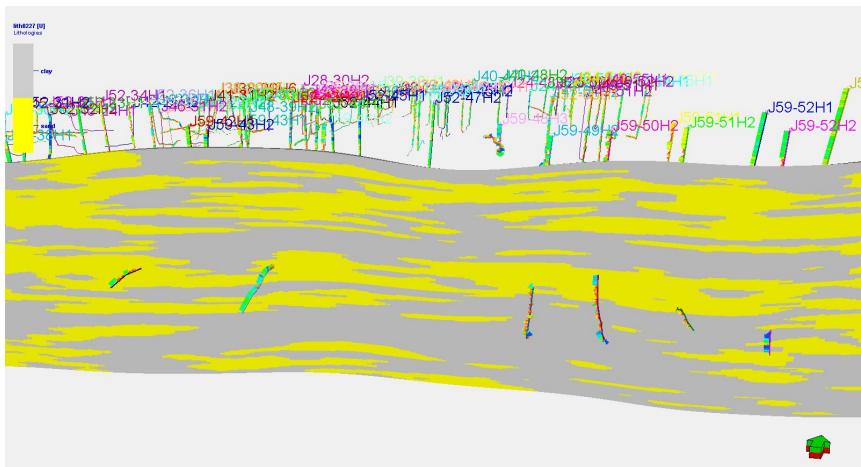
模拟结果显示:
剖面一致性较好
与水平井吻合度高
第3节 碳储地质建模工作流程
5.体积计算与模型质量检验
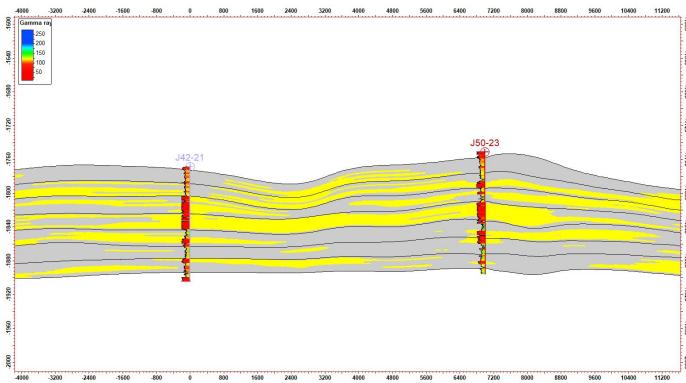
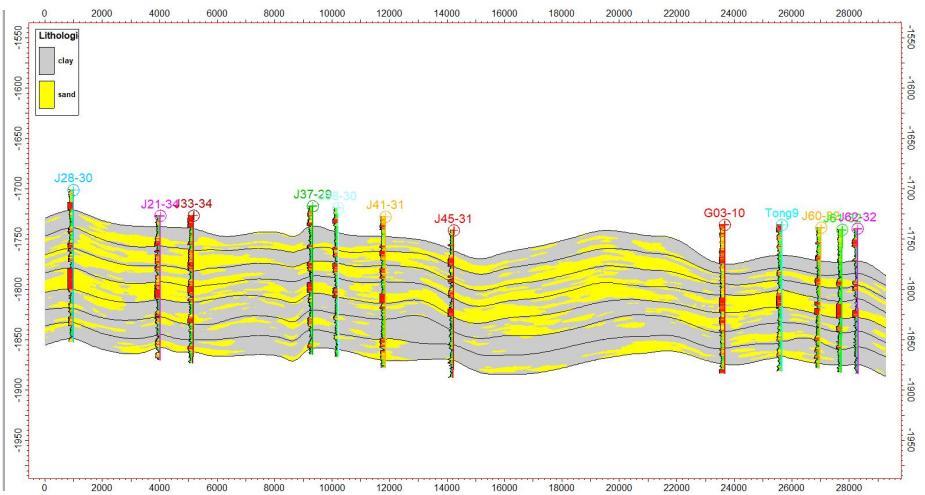
5.2 剖面验证
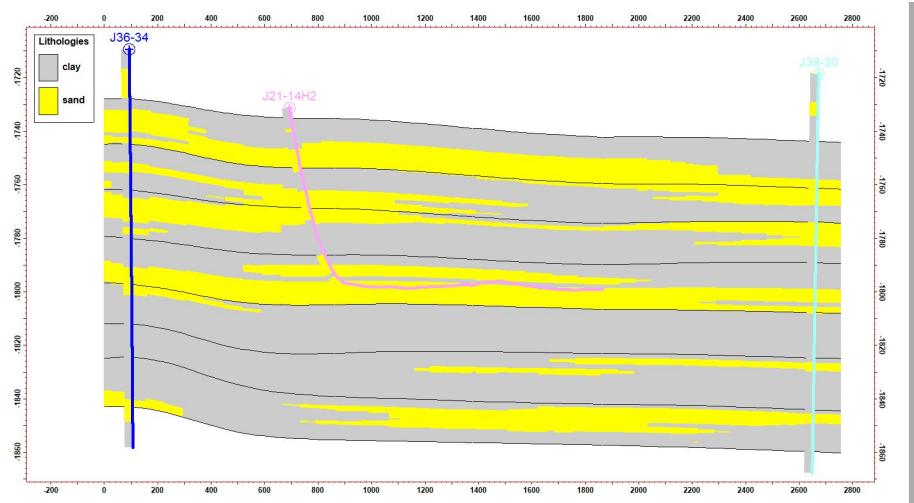
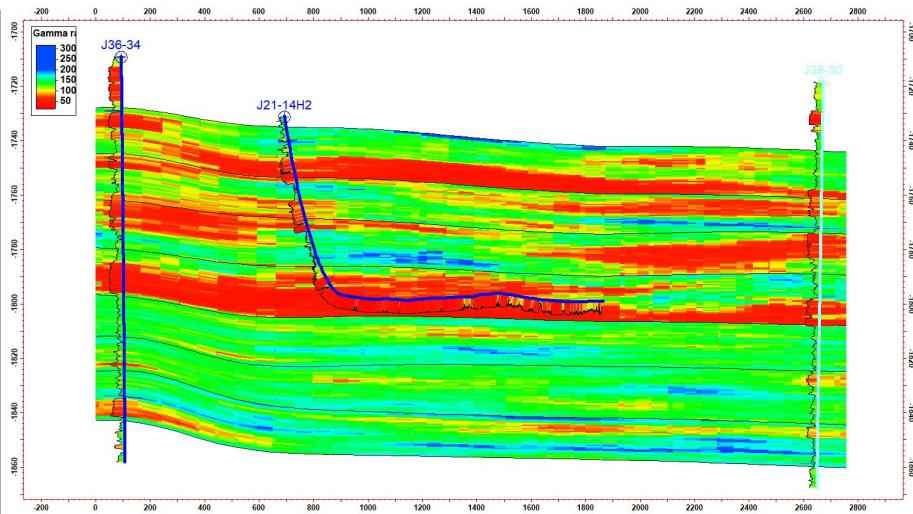
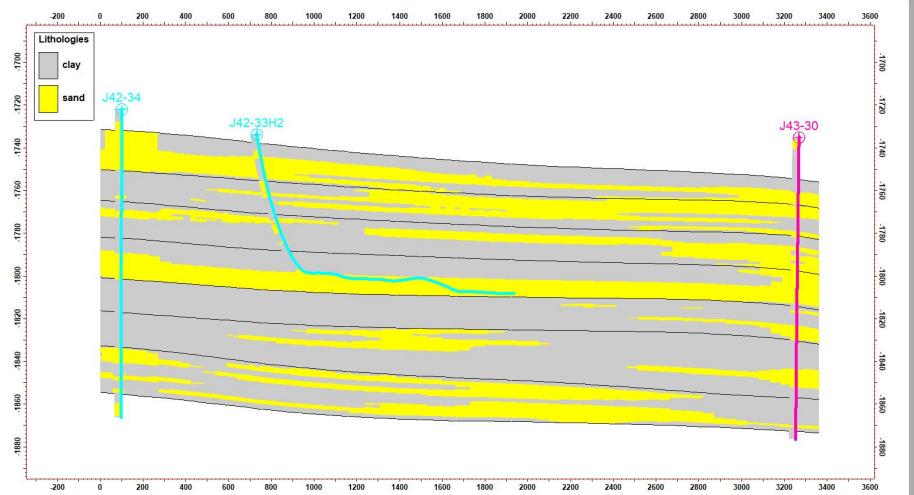
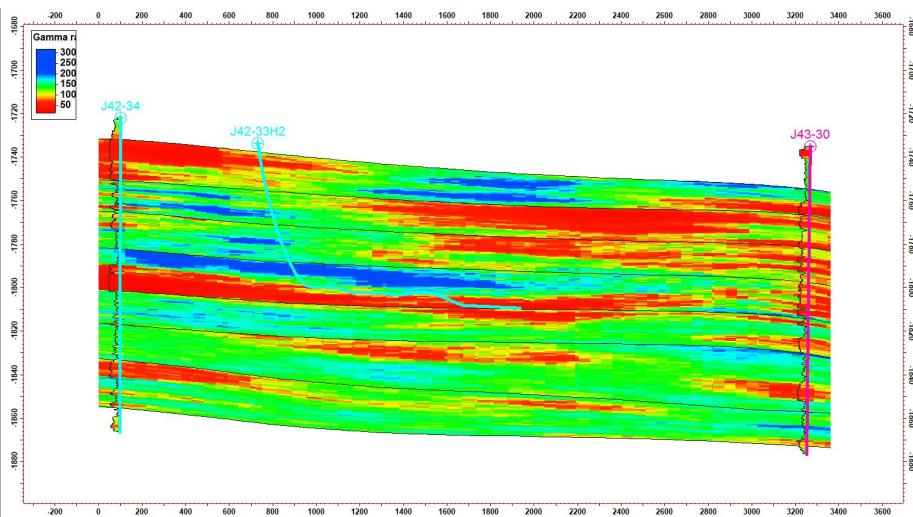
模拟结果显示:
剖面一致性较好
与水平井吻合度高
第3节 碳储地质建模工作流程
5.体积计算与模型质量检验
5.2 平剖一致性验证
ü 平/剖面一致性较好
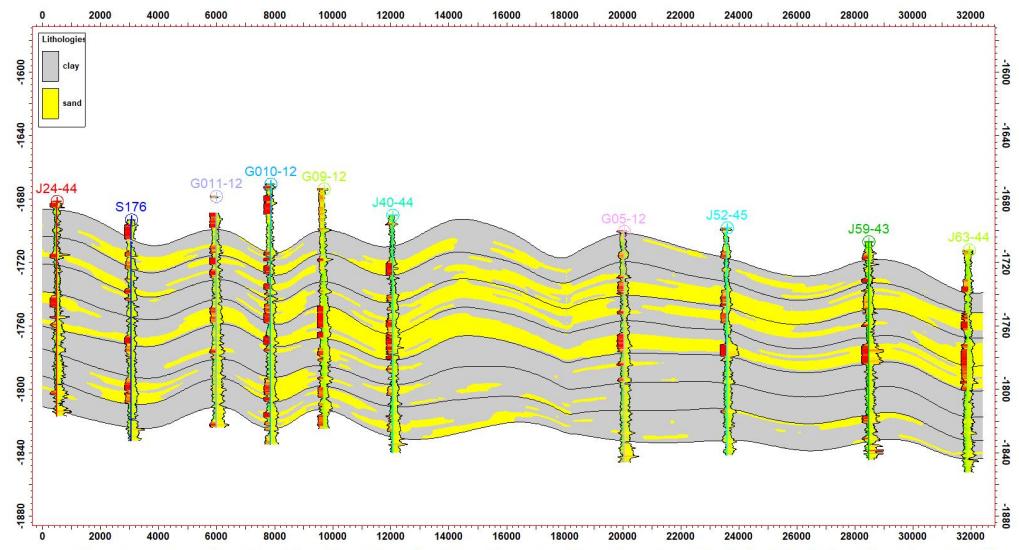

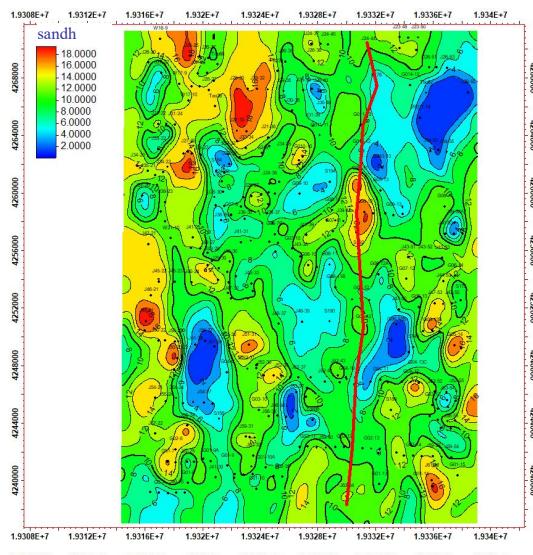
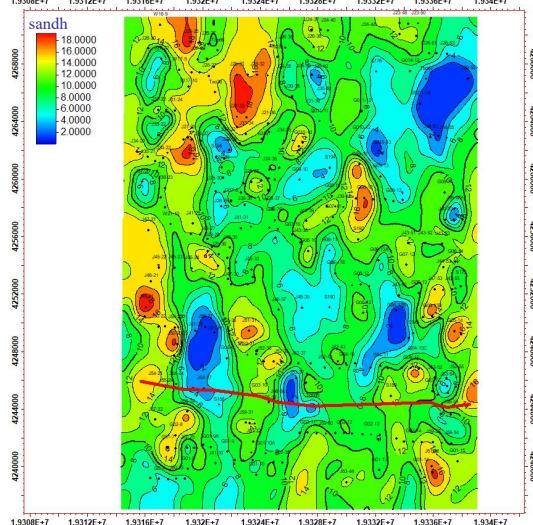
第3节 碳储地质建模工作流程
5.体积计算与模型质量检验
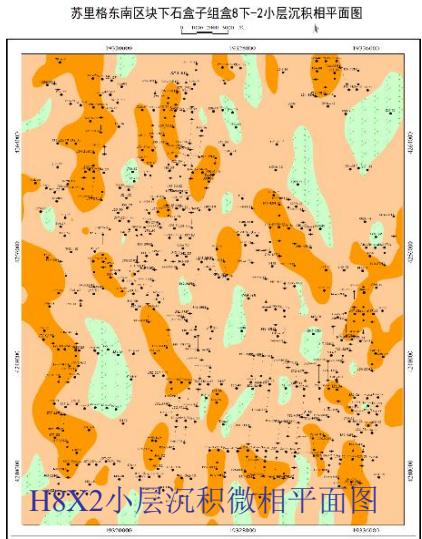
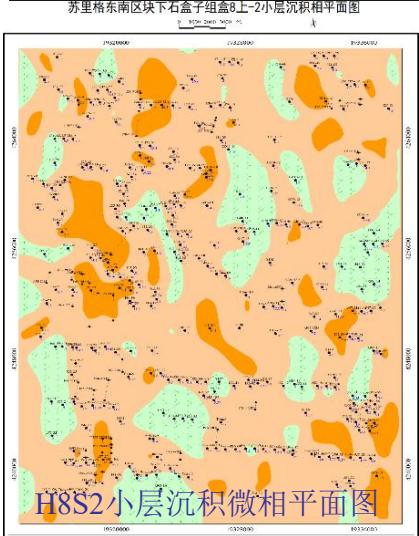
5.2 平剖一致性验证
苏里格东南区块下石盒子组盒8下-2小层沉积相平面图
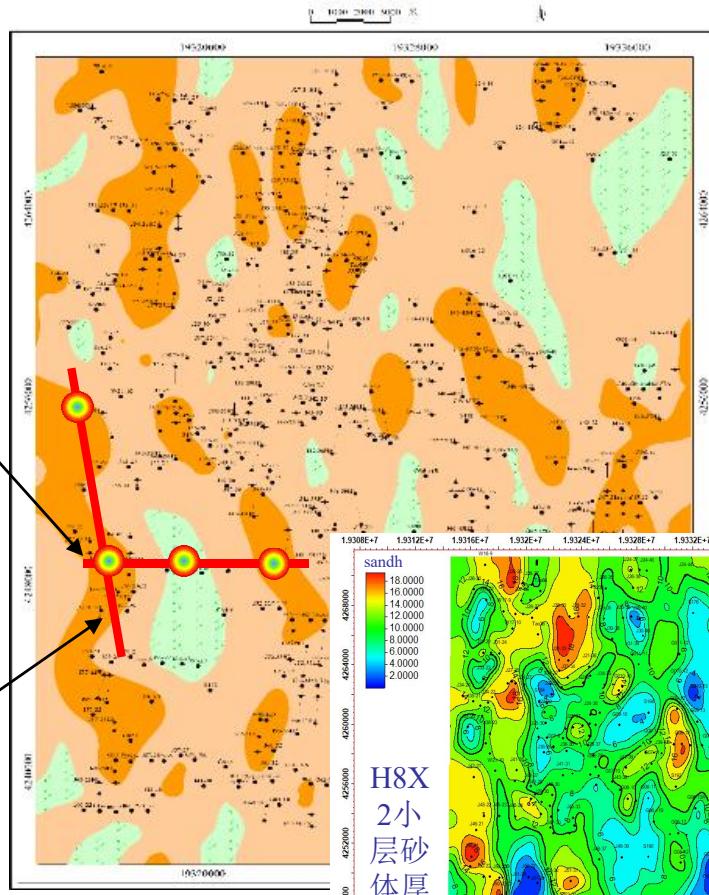
模型实现
第3节 碳储地质建模工作流程
5.体积计算与模型质量检验
模型粗化网格设计对比验证
Ø 清晰刻画最小单砂体
Ø 几乎无信息丢失
Ø 粗化前后厚度差异在2个网格单元内
Ø 单层/全模型粗化前后百分比变化细微
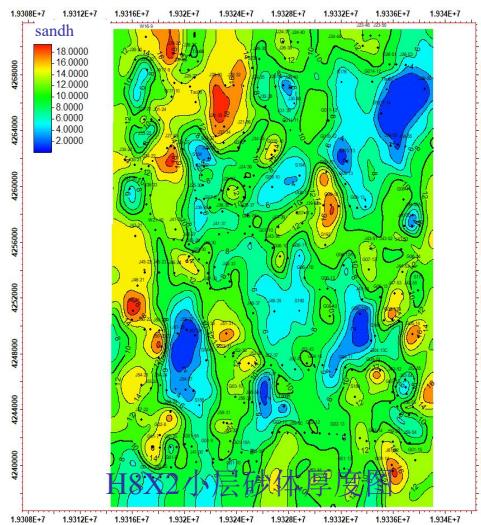
5.3 数据一致性验证
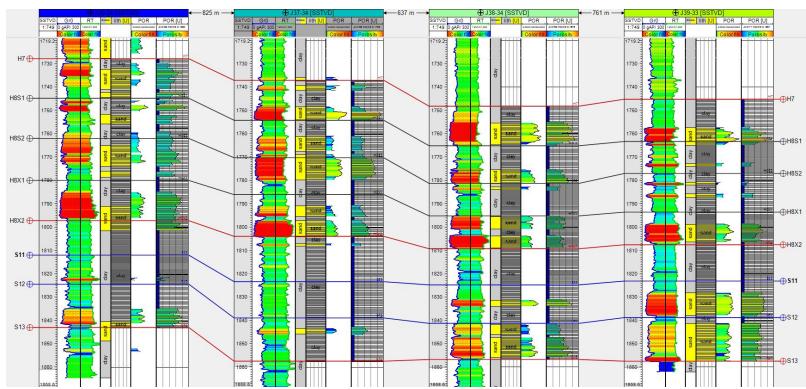
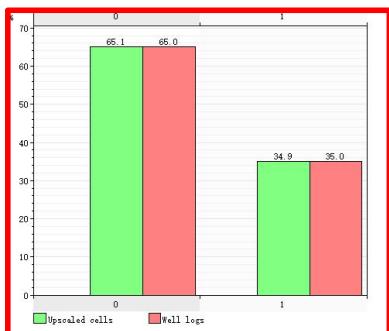
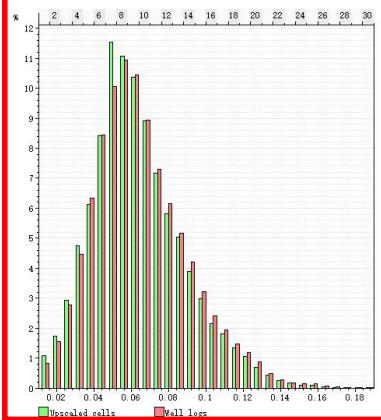
全模型
H8X2
第3节 碳储地质建模工作流程
5.体积计算与模型质量检验
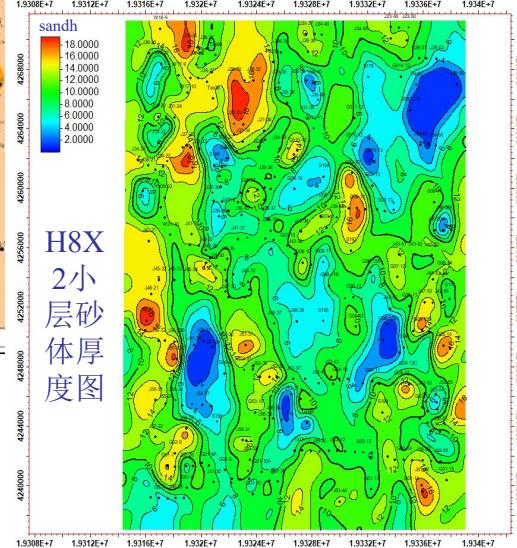
5.3 数据一致性验证
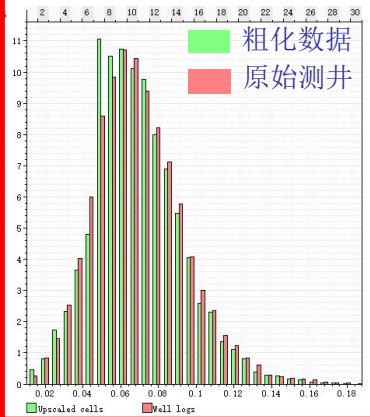
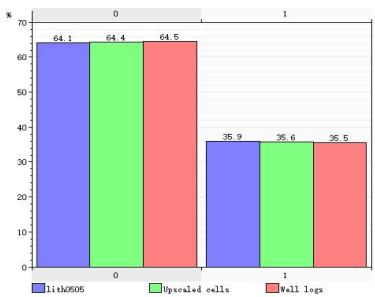
ü 模型-粗化-测井概率分布一致性较好
ü 模拟结果与地质概念分布一致性
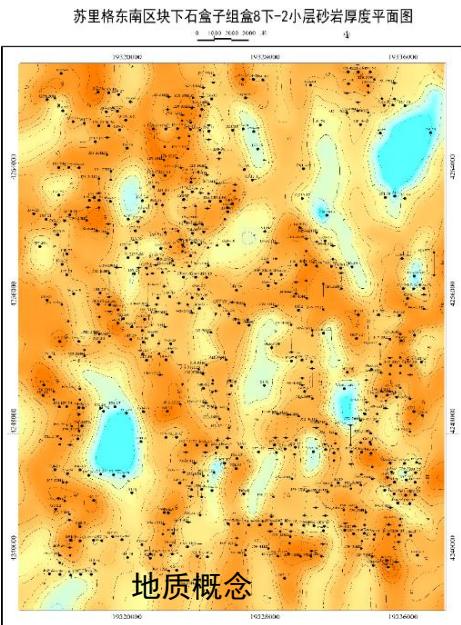
H8X2小层砂
体厚度图
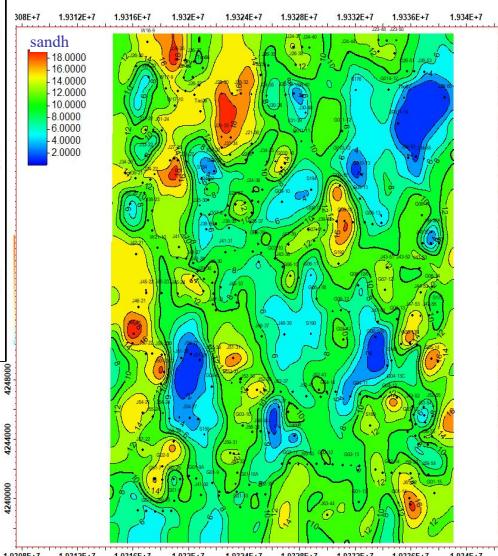
模拟结果
岩相模型
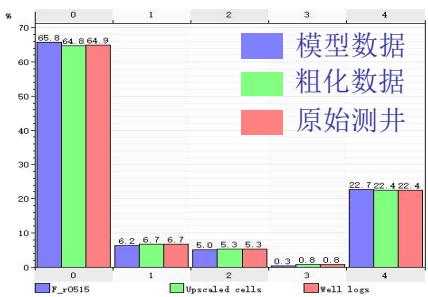
流体模型
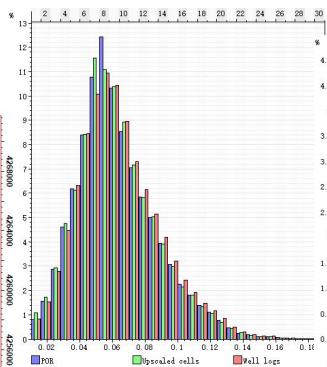
孔隙度
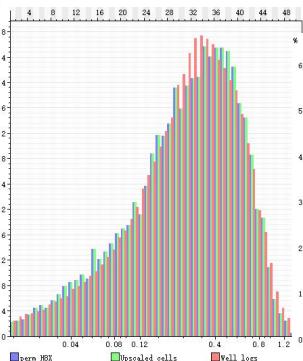
渗透率
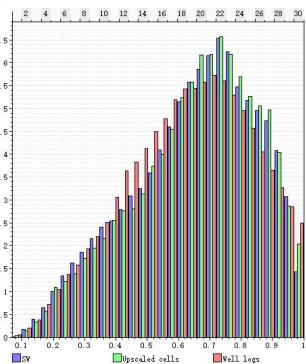
含油饱和度
模型统计结果
第3节 碳储地质建模工作流程
5.体积计算与模型质量检验
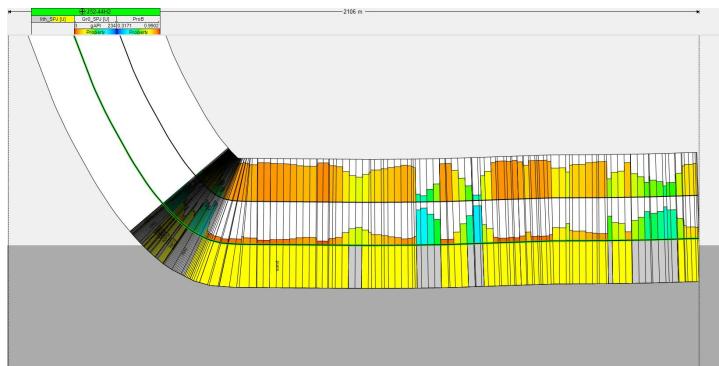
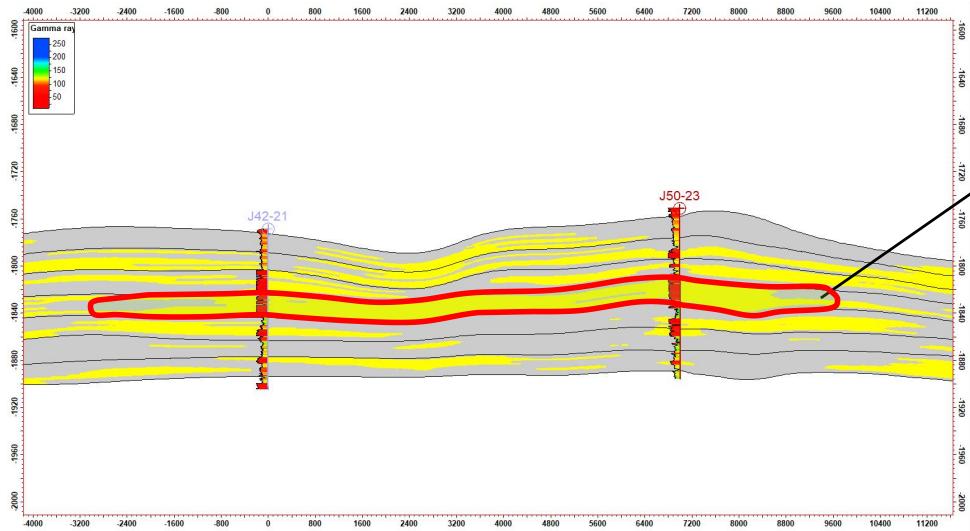
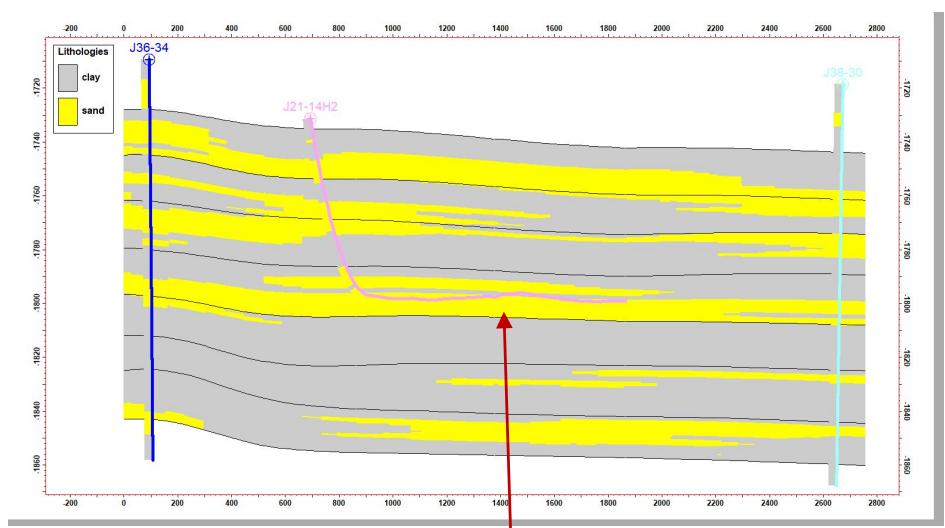
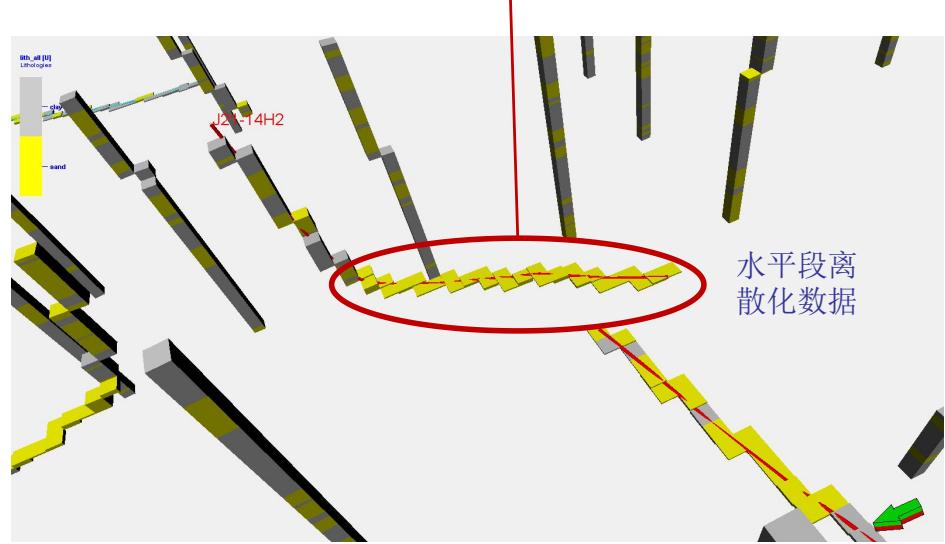
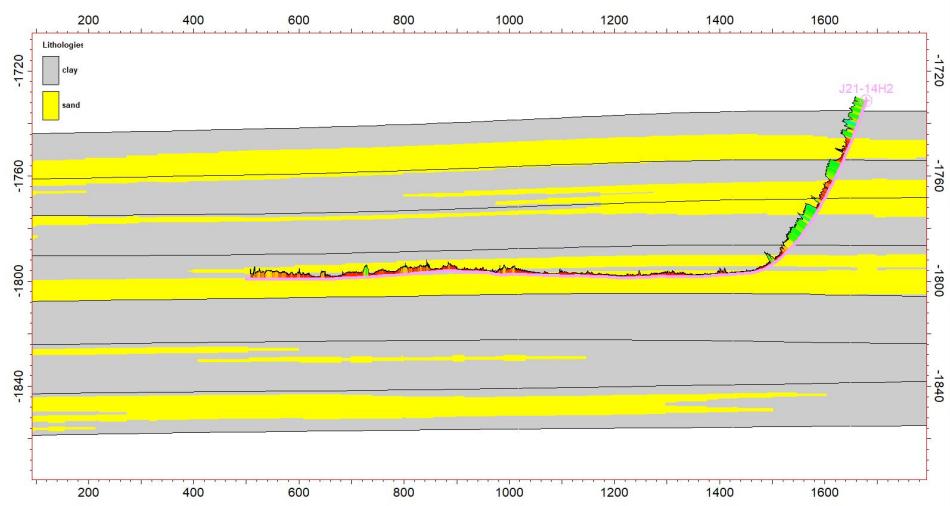
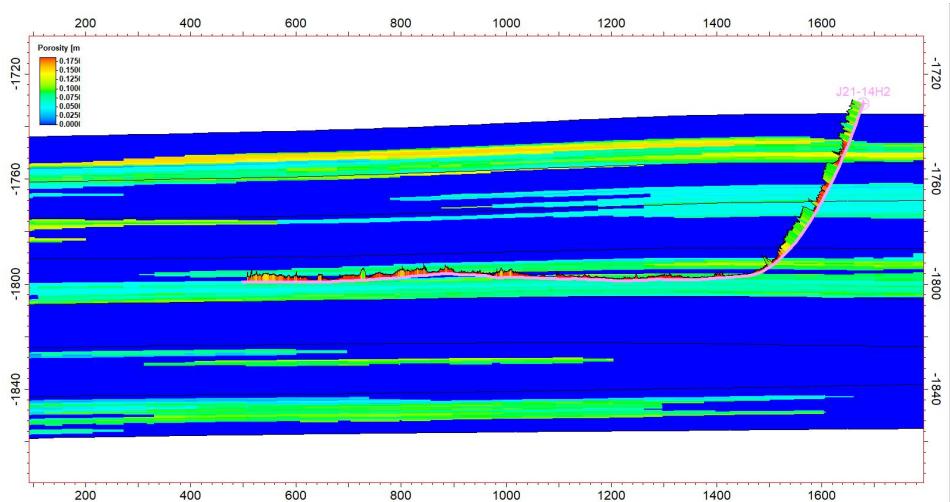
5.4 水平井数据验证
6.模型粗化输出
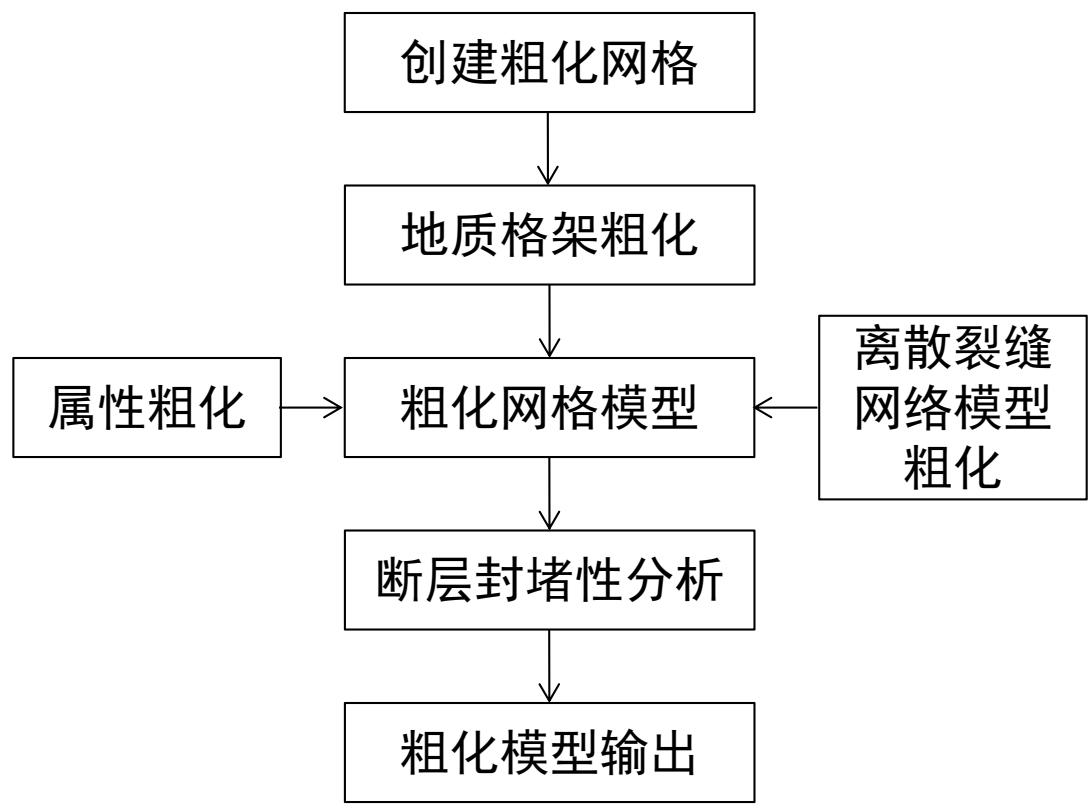
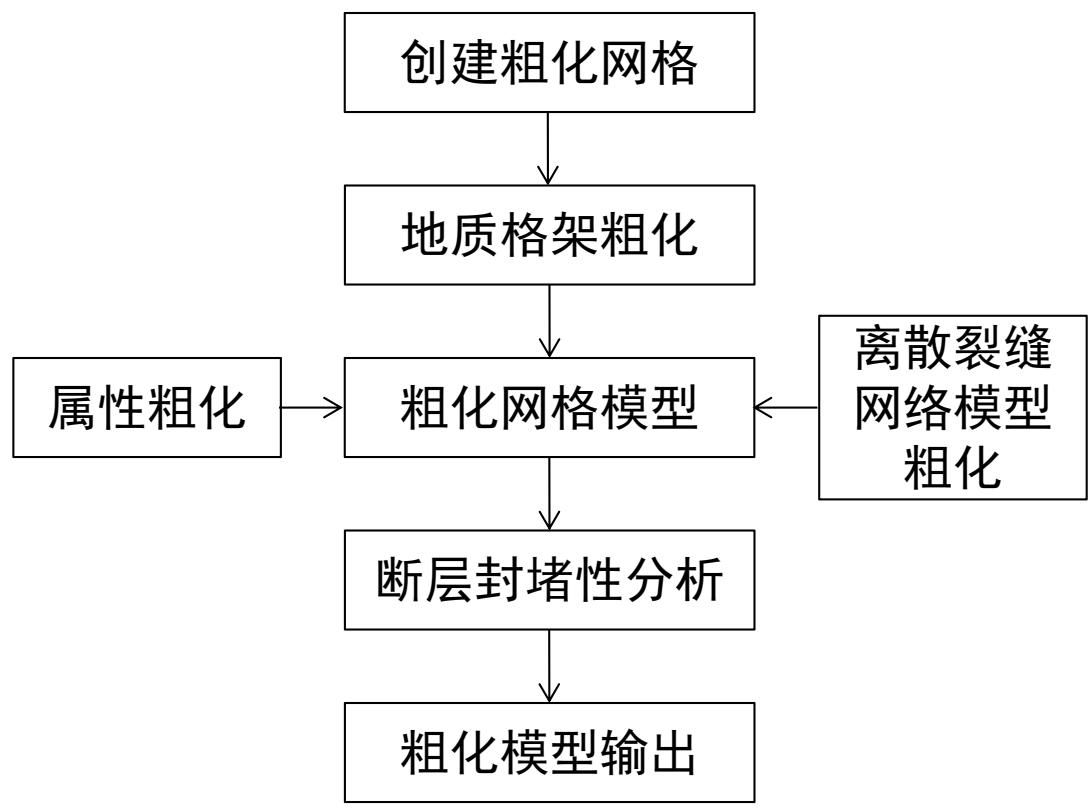
目的:CCUS数值模拟
计算机内存和速度的限制。
模型粗化是使细网格的精细地质模型“转化”为粗网格模型的过程,使等效粗网格模型能反映原模型的地质特征及流动响应。
6.模型粗化输出
碳储数模网格建立